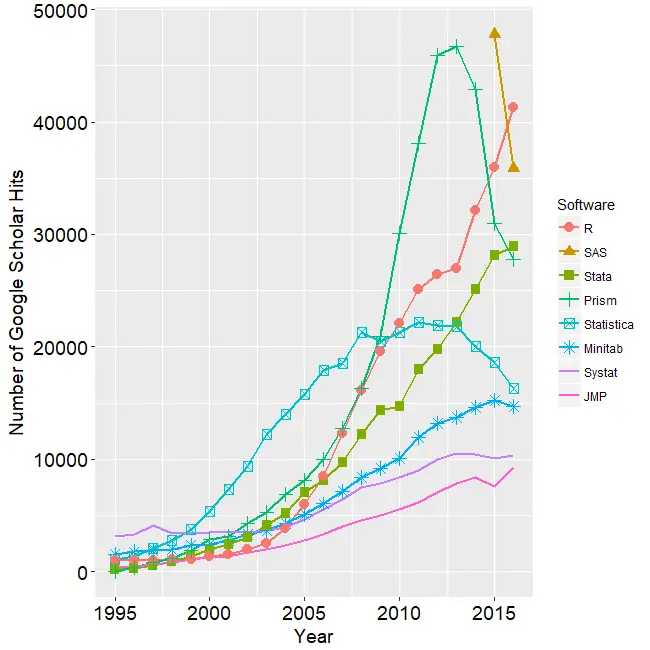
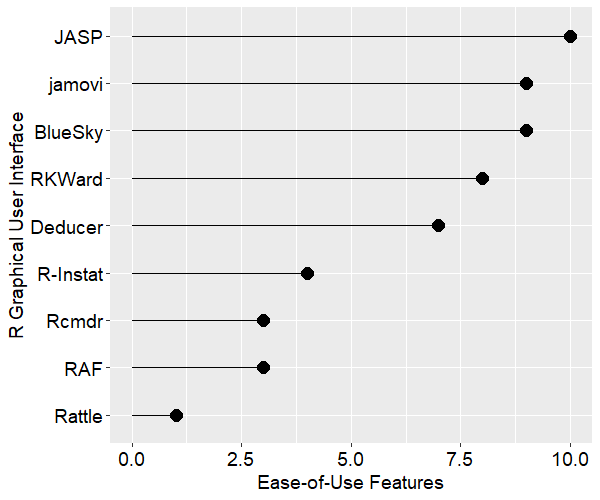
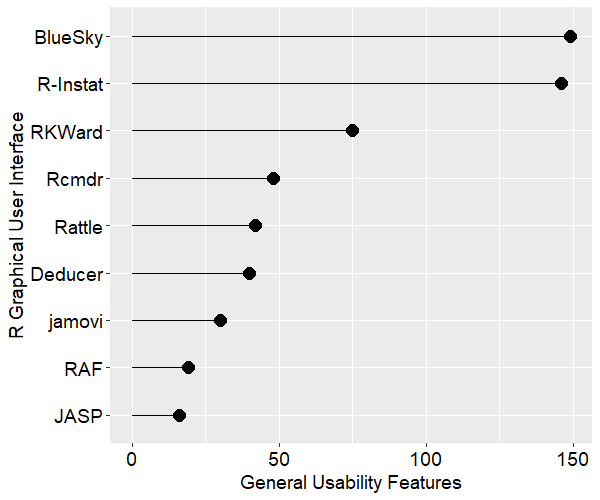
[An updated version of this article is here]
The open source R software for analytics has a reputation for being hard to learn. It certainly can be, especially for people who are already familiar with similar packages such as SAS, SPSS or Stata. Training and documentation that leverages their existing knowledge and points out where their previous knowledge is likely to mislead them can save much of frustration. This is the approach used in my books, R for SAS and SPSS Users and R for Stata Users as well as the workshops that are based on them.
Here is a list of complaints about R that I commonly hear from people learning it. In the comments section below, I’d like to hear about things that drive you crazy about R.
Misleading Function or Parameter Names (data=, sort, if)
The most difficult time people have learning R is when functions don’t do the “obvious” thing. For example when sorting data, SAS, SPSS and Stata users all use commands appropriately named “sort.” Turning to R they look for such a command and, sure enough, there’s one named exactly that. However, it does not sort data sets! Instead it sorts individual variables, which is often a very dangerous thing to do. In R, the “order” function sorts data sets and it does so in a somewhat convoluted way. However there are add-on packages that have sorting functions that work just as SAS/SPSS/Stata users would expect.
Perhaps the biggest shock comes when the new R user discovers that sorting is often not even needed by R. When other packages require sorting before they can do three common tasks:
- Summarizing / aggregating data
- Repeating an analysis for each group (“by” or “split file” processing)
- Merging files by key variables
R does not need to sort files before any of these tasks! So while sorting is a very helpful thing to be able to do for other reasons, R does not require it for these common situations.
Nonstandard Output
R’s output is often quite sparse. For example, when doing crosstabulation, other packages routinely provide counts, cell percents, row/column percents and even marginal counts and percents. R’s built-in table function (e.g. table(a,b)) provides only counts. The reason for this is that such sparse output can be readily used as input to further analysis. Getting a bar plot of a crosstabulation is as simple as barplot( table(a,b) ). This piecemeal approach is what allows R to dispense with separate output management systems such as SAS’ ODS or SPSS’ OMS. However there are add-on packages that provide more comprehensive output that is essentially identical to that provided by other packages.
Too Many Commands
Other statistics packages have relatively few analysis commands but each of them have many options to control their output. R’s approach is quite the opposite which takes some getting used to. For example, when doing a linear regression in SAS or SPSS you usually specify everything in advance and then see all the output at once: equation coefficients, ANOVA table, and so on. However, when you create a model in R, one command (summary) will provide the parameter estimates while another (anova) provides the ANOVA table. There is even a command “coefficients” that gets only that part of the model. So there are more commands to learn but fewer options are needed for each.
R’s commands are also consistent, working across all the modeling types that they might apply to. For example the “predict” function works the same way for all types of models that might make predictions.
Sloppy Control of Variables
When I learned R, it came as quite a shock that in a single analysis you can include variables from multiple data sets. That usually requires that the observations be in identical order in each data set. Over the years I have had countless clients come in to merge data sets that they thought had observations in the same order, but were not! It’s always safer to merge by key variables (like ID) if possible. So by enabling such analyses R seems to be asking for disaster. I still recommend merging files when possible by key variables before doing an analysis.
So why does R allow this “sloppiness”? It does so because it provides very useful flexibility. For example, might plot regression lines of variable X against variable Y for each of three groups on the same plot. Then you can add group labels directly onto the graph. This lets you avoid a legend that makes your readers look back and forth between the legend and lines. The label data would contain only three variables: the group labels and the coordinates at which you wish them to appear. That’s a data set of only 3 observations so merging that with the main data set makes little sense.
Loop-a-phobia
R has loops to control program flow, but people (especially beginners) are told to avoid them. Since loops are so critical to applying the same function to multiple variables, this seems strange. R instead uses the “apply” family of functions. You tell R to apply the function to either rows or columns. It’s a mental adjustment to make, but the result is the same.
Functions That Act Like Procedures
Many other packages, including SAS, SPSS and Stata have procedures or commands that do typical data analyses which go “down” through all the observations. They also have functions that usually do a single calculation across rows, such as taking the mean of some scores for each observation in the data set. But R has only functions and those functions can do both. How does it get away with that? Functions may have a preference to go down rows or across columns but for many functions you can use the “apply” family of functions to force then to go in either direction. So it’s true that in R, functions act like procedures and functions. Coming from other software, that’s a wild new idea.
Naming and Renaming Variables is Way Too Complicated
Often when people learn how R names and renames its variables they, well, freak out. There are many ways to name and rename variables because R stores the names as a character variable. Think of all the ways you know how to fiddle with character variables and you’ll realize that if you could use them all to name or rename variables, you have way more flexibility than the other data analysis packages. However, how long did it take you to learn all those tricks? Probably quite a while! So until someone needs that much flexibility, I recommend simply using R to read variable names from the same source as you read the data. When you need to rename them, use an add-on package that will let you do so in a style that is similar to SAS, SPSS or Stata. An example is here. You can convert to R’s built-in approach when you need more flexibility.
Inability to Analyze Multiple Variables
One of the first functions beginners typically learn is mean(X). As you might guess, it gets the mean of the X variable’s values. That’s simple enough. It also seems likely that to get the mean of two variables, you would just enter mean(X, Y). However that’s wrong because functions in R typically accept only single objects. The solution is to put those two variables into a single object such as a data frame: mean( data.frame(x,y) ). So the generalization you need to make isn’t from one variable to multiple variables, but rather from one object (a variable) to another (a data set). Since other software packages are not object oriented, this is a mental adjustment people have to make when coming to R from other packages. (Note to R gurus: I could have used colMeans but it does not make this example as clear.)
Poor Ability to Select Variable Sets
Most data analysis packages allow you to select variables that are next to one another in the data set (e.g. A–Z or A TO Z). R generally lacks this useful ability. It does have a “subset” function that allows the form A:Z, but that form works only in that function. There are many various work-arounds for this problem but most do seem rather convoluted compared to other software. Nothing’s perfect!
Too Much Complexity
People complain that R has too much complexity overall compared to other software. This comes from the fact that you can start learning software like SAS and SPSS with relatively few commands: the basic ones to read and analyze data. However when you start to become more productive you then have to learn whole new languages! To help reduce repitition in your programs you’ll need to learn the macro language. To use the output from one procedure in another, you’ll need to learn an output management system like SAS ODS or SPSS OMS. To add new capabilities you need to learn a matrix language like SAS IML, SPSS Matrix or Stata Mata. Each of these languages has its own commands and rules. There are also steps for tranferring data or parameters from one language to another. R has no need for that added complexity because it integrates all these capabilities into R itself. So it’s true that beginners have to see more complexity in R. Howevever, as they learn more about R, they begin to realize that there is actually less complexity and more power in R!
Lack of Graphical User Interface (GUI)
Like most other packages R’s full power is only accessible through programming. However unlike the others, it does not offer a standard GUI to help non-programmers do analyses. The two which are most like SAS, SPSS and Stata are R Commander and Deducer. While they offer enough analytic methods to make it through an undergraduate degree in statistics, they lack control when compared to a powerful GUI such as those used by SPSS or JMP. Worse, beginners must initially see a programming environment and then figure out how to find, install, and activate either GUI. Given that GUIs are aimed at people with fewer computer skills, this is a problem.
Conclusion
Most of the issues described above are misunderstandings caused by expecting R to work like other software that the person already knows. What examples like this have you come across?
Acknowledgements
Thanks to Patrick Burns and Tal Galili for their suggestions that improved this post.