It has been just a few months since I reviewed five free and open-source point-and-click graphical user interfaces (GUIs) to the R language. I plan to keep those reviews up to date as new features are added. BlueSky’s interface would be immediately familiar to anyone who had used SPSS, as its developers model it on that popular software. The BlueSky developers’ goal is to help people use R without having to learn to write computer code.
While the previous version of BlueSky offered dozens of fairly advanced modeling methods such as generalized linear models, random forests, and support vector machines, it lacked some simpler features. Version 5.40 (correction: this was previously listed as version 6.04) adds a dialog for logistic regression, which is essentially its glm dialog simplified to do only logistic regression.
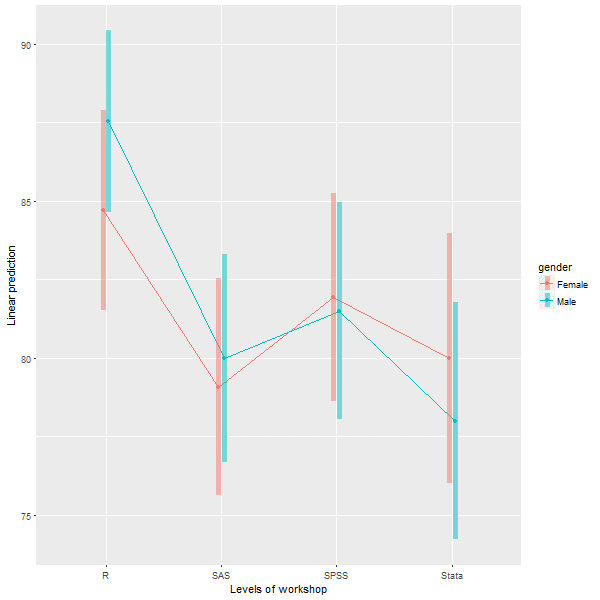
The Multi-Way ANOVA output has also been greatly enhanced, with the addition of a wide range of contrasts from the emmeans package, support for all three types of sums of squares, and plots for both post-hoc main-effects comparisons and interaction plots like this one:
Users of RStudio will be pleased that the BlueSky’s program editor now submits lines of code like RStudio does so you can step your way through a program line-by-line, by clicking the Run button repeatedly.
The new version also has functions to do string-to-date vice versa, which led me to realize I had totally missed the string and date functions that it already had. In the “Data> Compute” dialog, the functions for Arithmetic, Logical, Math, and String(1) are visible. But if you click on the “>>” arrow on the right, you’ll also see String (2), Conversion, Statistical, Random Numbers, and four different menus of Date functions.
The complete set of new features and bug fixes is below. You can read my full review of BlueSky here, and you download the software for free here. I plan to write about new features in other R GUIs, so stay tuned to my blog or follow me on twitter where I announce new posts. Happy computing!
NEW FEATURES:
=============
1) Added support for weighted datasets. This option is available in Data -> Set Weights. Once you specify the weighting variable we create a new dataset with rows replicated as defined in the weights. This is similar to what SPSS does internally. When you run frequencies, independent sample t-tests, graphics commands, statistical tests etc on the new dataset (in BlueSky Statistics) with the rows replicated you will see results identical to those in SPSS.
2) Added the option to specify a weighting variable in Linear and Logistic Regression. This allows an optional vector of weights to be used during the fitting process (i.e. the weighted least-squares solution).
3) Added support for logistic regression under ‘Model Fitting’. Once the model is built, you can score the dataset, optionally obtain a confusion matrix, model statistics, and a ROC curve by selecting the model and clicking score. This is available on the top right-hand corner of the main application window.
4) We have updated the “Multi Way Anova” dialog with following capabilities:
- display contrasts.
- interaction plots.
- support for type I, type II and type III tests.
- pairwise comparison.
5) New reshape dialog with simplified R syntax has been added, using the tidyr package.
6) The “Multi variable one sample T-Test” and “Multi variable independent sample T-Test(with factor)” have been updated to allow you to specify the alternative hypothesis.
7) Added capabilities to support date manipulations.
- The “String to date” dialog allows you to convert string to POSIXct date class.
- The “Date to string” dialog allows you to convert the date (POSIXct and Date class) to string.
8) Simplified the syntax for frequencies and factor analysis.
9) If you launch a second instance of BlueSky Statistics the message that gets displayed has been improved. NOTE: You can only have one BlueSky Statistics instance running at a time.
10) We have improved the ability to browse the contents of the output window in BlueSky Statistics. This can be accessed from the menu (Layout > Show Navigation Tree).
11) Items in the output window can now be deleted. To delete an item from the output, just right click on the item(table/text/graphics) and choose the “Delete” option.
12) To make the output visually more appealing, we have introduced an option to hide the R syntax that gets displayed in the output window. This is controlled by an option in the configuration window ( Tools > Configuration Settings > Output tab ). By default we hide the R syntax in the output window.
13) When the option to show R syntax in the output is turned on ( Tools > Configuration Settings > Output tab ) and you resize the output window, we wrap the R syntax so that it is always visible.
14) To run any line of R syntax just place the cursor on that line and hit the RUN button, you don’t have to select the entire line.
15) If you want to run your R script line by line, place your cursor on the first line and hit RUN, the cursor will automatically move to the next line and you can hit the RUN button again.
This feature will work for simple R syntax which does not span multiple lines.
Example 1: 3 lines below work
a=10
b=20
c=a+b
Example 2: 4 lines below will not work
if(TRUE)
{
print(“Great”)
}
16)Added helpful hints to indicate you have reached the beginning and end of a dataset when scrolling wide datasets. This is available on the paging controls on the bottom right-hand corner of the screen.
17) Application launch is now faster.
18) In the BlueSky Statistics syntax editor, just like a comma, the pipe (%>%) can be used to break a long R code statement.
19) When the application launches, we open a new blank dataset this has been populated with zeros. You can right click on a row to delete a row or go into ‘Data -> Delete Variables’ to delete variables.
20) Clicking on a variable name in the data grid sorts in ascending order by that variable name. Clicking again sorts in descending order.
BUG FIXES:
=============
1) Fixed an issue with factor analysis when saving scores using the regression method.
2) Fixed an issue when re-editing factor levels that were previously changed in the variable grid. This would result in the dialog not functioning correctly and incorrect levels being added.
3) Fixed an issue when you closed the empty dataset that gets created when BlueSky Statistics is launched and then attempted to save open datasets- those datasets would not get saved correctly.
4) Fixed an issue that was limiting the number of variables that Factor Analysis can be run across.
5) Within block commands that use ‘local()’, cat(“\n”) can now be printed in the output to leave some extra spaces.
6) When you added a new factor variable and renamed the variable using the user interface and then tried to add new levels – this did not work and has been fixed.
7) Add new factor variable. Click in the cell where the new variable name is shown. Cell goes in edit mode. Now add new factor levels to this new variable. Switch to the data grid and select a different level. Switch back to ‘Variables’ tab and the application crashes. This has been fixed.
8) When any existing factor level name is modified using the user interface, a blank level automatically gets added. If you try to modify the level, it does not take effect. This has been addressed.
9) Disable data grid navigation buttons (on the lower right-hand side of the data grid) if there are less than 16 columns in the dataset.
10) Changing factor levels was not working because one or more levels had a single quote in the level name.
11) Aggregate control fixed: Text above the drop-down (that contains mean, median etc.) was getting chopped off. Similar issue with the label text above a textbox (which was almost at the bottom of the dialog).
12) Fixed significance codes for:
- One Sample T Test and Independent Sample T Test
- Multivariable one sample t-test and Multivariable Independent one sample t-test (with factor)
13) Fixed a defect: Select some syntax and hit RUN. After execution, the cursor goes to the top of the script. Now it moves to the next line.
14) Data grid navigation buttons are disabled if either end of the datagrid is reached. If there are no more columns on the right, the right navigation button is disabled. If there are no more columns on the left then left navigation button is disabled.
15) Left navigation tree in the output window is fixed for look and feel. It now has a cleaner look. To access left navigation, go to Layout -> Show navigation tree
16) In the R syntax editor, we now ignore square, curly and round brackets that appear inside single or double quotes. See example below:
grepl(“[“, “a[b”, fixed = TRUE)
The website still has Ver 5.35 as the download. Is there a place to obtain the new version?
Hi Francis,
I checked with the developers and they were just putting the new version online. I verified that it’s there now. Note that the post initially referred to the version as 6.04 when it’s actually 5.40. My mistake!
Thanks for reporting it!
Cheers,
Bob
Hello,
I would like to analyse a data set from a survey institute. It contains a weighting variable with decimal places. (BlueSky Ver 7.30)
It seems, BlueSky doesn’t use decimal places into account, but uses the first digit. 1.2 is weighted the same as 1.6 and all variables with weights less than 1 are removed. Is this the way BlueSky is supposed to work?
It seems that I cannot use BlueSky for this type of survey data set. But I want to rule out that I am making some kind of mistake.
Thanks!
Hi Mats,
I’m afraid I don’t know, but if you look at the code to see the function it’s using, then you can look at the R help file to see if decimal weights are accepted by that function. BlueSky is completely dependent on what the R functions do.
Cheers,
Bob