Below is the latest update to The Popularity of Data Science Software. It contains an analysis of the tools used in the most recent complete year of scholarly articles. The section is also integrated into the main paper itself.
New software covered includes: Amazon Machine Learning, Apache Mahout, Apache MXNet, Caffe, Dataiku, DataRobot, Domino Data Labs, GraphPad Prism, IBM Watson, Pentaho, and Google’s TensorFlow.
Software dropped includes: Infocentricity (acquired by FICO), SAP KXEN (tiny usage), Tableau, and Tibco. The latter two didn’t fit in with the others due to their limited selection of advanced analytic methods.
Scholarly Articles
Scholarly articles provide a rich source of information about data science tools. Their creation requires significant amounts of effort, much more than is required to respond to a survey of tool usage. The more popular a software package is, the more likely it will appear in scholarly publications as an analysis tool, or even an object of study.
Since graduate students do the great majority of analysis in such articles, the software used can be a leading indicator of where things are headed. Google Scholar offers a way to measure such activity. However, no search of this magnitude is perfect; each will include some irrelevant articles and reject some relevant ones. Searching through concise job requirements (see previous section) is easier than searching through scholarly articles; however only software that has advanced analytical capabilities can be studied using this approach. The details of the search terms I used are complex enough to move to a companion article, How to Search For Data Science Articles. Since Google regularly improves its search algorithm, each year I re-collect the data for the previous years.
Figure 2a shows the number of articles found for the more popular software packages (those with at least 750 articles) in the most recent complete year, 2016. To allow ample time for publication, insertion into online databases, and indexing, the was data collected on 6/8/2017.
SPSS is by far the most dominant package, as it has been for over 15 years. This may be due to its balance between power and ease-of-use. R is in second place with around half as many articles. SAS is in third place, still maintaining a substantial lead over Stata, MATLAB, and GraphPad Prism, which are nearly tied. This is the first year that I’ve tracked Prism, a package that emphasizes graphics but also includes statistical analysis capabilities. It is particularly popular in the medical research community where it is appreciated for its ease of use. However, it offers far fewer analytic methods than the other software at this level of popularity.
Note that the general-purpose languages: C, C++, C#, FORTRAN, MATLAB, Java, and Python are included only when found in combination with data science terms, so view those counts as more of an approximation than the rest.
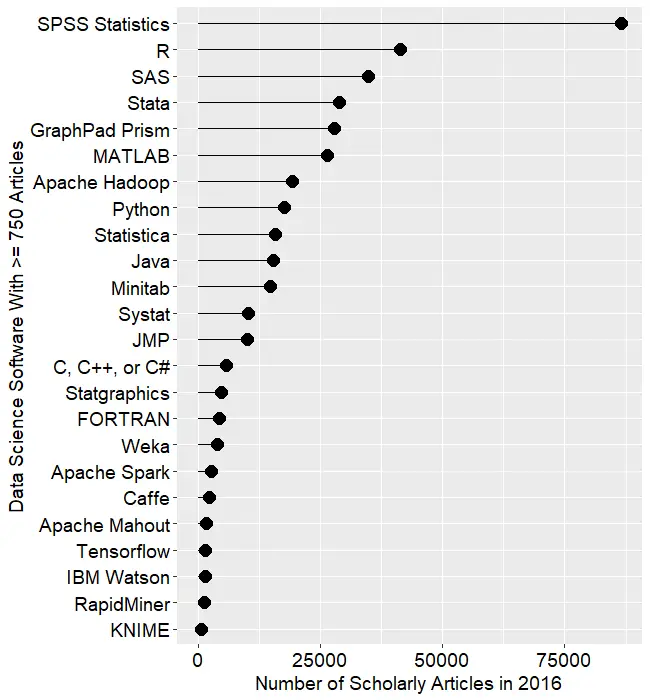
Figure 2a. Number of scholarly articles found in the most recent complete year (2016) for the more popular data science software. To be included, software must be used in at least 750 scholarly articles.
The next group of packages goes from Apache Hadoop through Python, Statistica, Java, and Minitab, slowly declining as they go.
Both Systat and JMP are packages that have been on the market for many years, but which have never made it into the “big leagues.”
From C through KNIME, the counts appear to be near zero, but keep in mind that each are used in at least 750 journal articles. However, compared to the 86,500 that used SPSS, they’re a drop in the bucket.
Toward the bottom of Fig. 2a are two similar packages, the open source Caffe and Google’s Tensorflow. These two focus on “deep learning” algorithms, an area that is fairly new (at least the term is) and growing rapidly.
The last two packages in Fig 2a are RapidMiner and KNIME. It has been quite interesting to watch the competition between them unfold for the past several years. They are both workflow-driven tools with very similar capabilities. The IT advisory firms Gartner and Forester rate them as tools able to hold their own against the commercial titans, SPSS and SAS. Given that SPSS has roughly 75 times the usage in academia, that seems like quite a stretch. However, as we will soon see, usage of these newcomers are growing, while use of the older packages is shrinking quite rapidly. This plot shows RapidMiner with nearly twice the usage of KNIME, despite the fact that KNIME has a much more open source model.
Figure 2b shows the results for software used in fewer than 750 articles in 2016. This change in scale allows room for the “bars” to spread out, letting us make comparisons more effectively. This plot contains some fairly new software whose use is low but growing rapidly, such as Alteryx, Azure Machine Learning, H2O, Apache MXNet, Amazon Machine Learning, Scala, and Julia. It also contains some software that is either has either declined from one-time greatness, such as BMDP, or which is stagnating at the bottom, such as Lavastorm, Megaputer, NCSS, SAS Enterprise Miner, and SPSS Modeler.

Figure 2b. The number of scholarly articles for the less popular data science (those used by fewer than 750 scholarly articles in 2016.
While Figures 2a and 2b are useful for studying market share as it stands now, they don’t show how things are changing. It would be ideal to have long-term growth trend graphs for each of the analytics packages, but collecting that much data annually is too time consuming. What I’ve done instead is collect data only for the past two complete years, 2015 and 2016. This provides the data needed to study year-over-year changes.
Figure 2c shows the percent change across those years, with the “hot” packages whose use is growing shown in red (right side); those whose use is declining or “cooling” are shown in blue (left side). Since the number of articles tends to be in the thousands or tens of thousands, I have removed any software that had fewer than 500 articles in 2015. A package that grows from 1 article to 5 may demonstrate 500% growth, but is still of little interest.
 Figure 2c. Change in the number of scholarly articles using each software in the most recent two complete years (2015 to 2016). Packages shown in red are “hot” and growing, while those shown in blue are “cooling down” or declining.
Figure 2c. Change in the number of scholarly articles using each software in the most recent two complete years (2015 to 2016). Packages shown in red are “hot” and growing, while those shown in blue are “cooling down” or declining.
Caffe is the data science tool with the fastest growth, at just over 150%. This reflects the rapid growth in the use of deep learning models in the past few years. The similar products Apache MXNet and H2O also grew rapidly, but they were starting from a mere 12 and 31 articles respectively, and so are not shown.
IBM Watson grew 91%, which came as a surprise to me as I’m not quite sure what it does or how it does it, despite having read several of IBM’s descriptions about it. It’s awesome at Jeopardy though!
While R’s growth was a “mere” 14.7%, it was already so widely used that the percent translates into a very substantial count of 5,300 additional articles.
In the RapidMiner vs. KNIME contest, we saw previously that RapidMiner was ahead. From this plot we also see that it’s continuing to pull away from KNIME with quicker growth.
From Minitab on down, the software is losing market share, at least in academia. The variants of C and Java are probably losing out a bit to competition from several different types of software at once.
In just the past few years, Statistica was sold by Statsoft to Dell, then Quest Software, then Francisco Partners, then Tibco! Did its declining usage drive those sales? Did the game of musical chairs scare off potential users? If you’ve got an opinion, please comment below or send me an email.
The biggest losers are SPSS and SAS, both of which declined in use by 25% or more. Recall that Fig. 2a shows that despite recent years of decline, SPSS is still extremely dominant for scholarly use.
I’m particularly interested in the long-term trends of the classic statistics packages. So in Figure 2d I have plotted the same scholarly-use data for 1995 through 2016.

Figure 2d. The number of scholarly articles found in each year by Google Scholar. Only the top six “classic” statistics packages are shown.
As in Figure 2a, SPSS has a clear lead overall, but now you can see that its dominance peaked in 2009 and its use is in sharp decline. SAS never came close to SPSS’ level of dominance, and its use peaked around 2010. GraphPAD Prism followed a similar pattern, though it peaked a bit later, around 2013.
Note that the decline in the number of articles that used SPSS, SAS, or Prism is not balanced by the increase in the other software shown in this particular graph. Even adding up all the other software shown in Figures 2a and 2b doesn’t account for the overall decline. However, I’m looking at only 46 out of over 100 data science tools. SQL and Microsoft Excel could be taking up some of the slack, but it is extremely difficult to focus Google Scholar’s search on articles that used either of those two specifically for data analysis.
Since SAS and SPSS dominate the vertical space in Figure 2d by such a wide margin, I removed those two curves, leaving only two points of SAS usage in 2015 and 2016. The result is shown in Figure 2e.

Figure 2e. The number of scholarly articles found in each year by Google Scholar for classic statistics packages after the curves for SPSS and SAS have been removed.
Freeing up so much space in the plot allows us to see that the growth in the use of R is quite rapid and is pulling away from the pack. If the current trends continue, R will overtake SPSS to become the #1 software for scholarly data science use by the end of 2018. Note however, that due to changes in Google’s search algorithm, the trend lines have shifted before as discussed here. Luckily, the overall trends on this plot have stayed fairly constant for many years.
The rapid growth in Stata use seems to be finally slowing down. Minitab’s growth has also seemed to stall in 2016, as has Systat’s. JMP appears to have had a bit of a dip in 2015, from which it is recovering.
The discussion above has covered but one of many views of software popularity or market share. You can read my analysis of several other perspectives here.
Thank you for a great article.
Are there any chances that you will share your code?
Hi Sander,
I just sent it to you via Gmail. If anyone else would like to fiddle around with it, let me know. Keep in mind that you can’t simply add new data for each new year, it all has to be collected from scratch annually because the Google search algorithm changes quite a lot, yielding discontinuities in the curves.
Cheers,
Bob
Hi Bob,
I’m working on analysis that would build off of your work here. Would you be willing to send me the scripting that you used? Thanks