BlueSky Statistics is an easy-to-use menu system that uses the R language to do all its work. My detailed review of BlueSky is available here, and a brief comparison of the various menu systems for R is here. I’ve just released the BlueSky Statistics 7.1 User Guide in printed form on the world’s largest independent bookstore, Lulu.com. A description and detailed table of contents are available here.
Cover design by Kiran Rafiq.
I’ve also released the BlueSky Statistics 7.1 Intro Guide. It is a complete subset of the User Guide, and you can download it for free here (if you have trouble downloading it, your company may have security blocking Microsoft OneDrive; try it at home). Its description and table of contents are here, and soon you will also be able to purchase a printed copy of it from Lulu.com.
Cover design by Kiran Rafiq.
I’m enthusiastic about getting feedback on these books. If you have comments or suggestions, please send them to me at muenchen.bob at gmail dot com.
Publishing with Lulu.com has been a very pleasant experience. They put the author in complete control, making one responsible for every detail of the contents, obtaining reviewers, creating a cover file that includes the front, back, and spine of the book to match the dimensions of the book (e.g. more pages means wider spine, etc.) Advertising is left up to the writer as well, hence this blog post! If you are thinking about writing a book, I highly recommend both Lulu.com and getting a cover design from 99designs.com. The latter let me run a contest in which a dozen artists submitted several ideas each. Their built-in survey system let me ask many colleagues for their opinions to help me decide. Altogether, it was a very interesting experience.
To follow the progress of these and other R related books, subscribe to my blog, or follow me on Twitter.
The BlueSky Statistics graphical user interface (GUI) for the R language has added quite a few new features (described below). I’m also working on a BlueSky User Guide, a draft of which you can read about and download here. [Update: don’t download that, get the full Intro Guide download instead.] Although I’m spending a lot of time on BlueSky, I still plan to be as obsessive as ever about reviewing all (or nearly all) of the R GUIs, which is summarized here.
The new data management features in BlueSky are:
Date Order Check — this lets you quickly check across the dates stored in many variables, and it reports if it finds any rows whose dates are not always increasing from left to right.
Find Duplicates – generates a report of duplicates and saves a copy of the data set from which the duplicates are removed. Duplicates can be based on all variables, or a set of just ID variables.
Select First/Last Observation per Group – finding the first or last observation in a group can create new datasets from the “best” or “worst” case in each group, find the most current record, and so on.
Model Fitting / Tuning
One of the more interesting features in BlueSky is its offering of what they call Model Fitting and Model Tuning. Model Fitting gives you direct control over the R function that does the work. That provides precise control over every setting, and it can teach you the code that the menus create, but it also means that model tuning is up to you to do. However, it does standardize scoring so that you do not have to keep up with the wide range of parameters that each of those functions need for scoring. Model Tuning controls models through the caret package, which lets you do things like K-fold cross-validation and model tuning. However, it does not allow control over every model setting.
New Model Fitting menu items are:
Cox Proportional Hazards Model: Cox Single Model
Cox Multiple Models
Cox with Formula
Cox Stratified Model
Extreme Gradient Boosting
KNN
Mixed Models
Neural Nets: Multi-layer Perceptron
NeuralNets (i.e. the package of that name)
Quantile Regression
There are so many Model Tuning entries that it’s easier to just paste in the list I updated on the main BlueSkly review that I updated earlier this morning:
Model Tuning: Adaboost Classification Trees
Model Tuning: Bagged Logic Regression
Model Tuning: Bayesian Ridge Regression
Model Tuning: Boosted trees: gbm
Model Tuning: Boosted trees: xgbtree
Model Tuning: Boosted trees: C5.0
Model Tuning: Bootstrap Resample
Model Tuning: Decision trees: C5.0tree
Model Tuning: Decision trees: ctree
Model Tuning: Decision trees: rpart (CART)
Model Tuning: K-fold Cross-Validation
Model Tuning: K Nearest Neighbors
Model Tuning: Leave One Out Cross-Validation
Model Tuning: Linear Regression: lm
Model Tuning: Linear Regression: lmStepAIC
Model Tuning: Logistic Regression: glm
Model Tuning: Logistic Regression: glmnet
Model Tuning: Multi-variate Adaptive Regression Splines (MARS via earth package)
Model Tuning: Naive Bayes
Model Tuning: Neural Network: nnet
Model Tuning: Neural Network: neuralnet
Model Tuning: Neural Network: dnn (Deep Neural Net)
Model Tuning: Neural Network: rbf
Model Tuning: Neural Network: mlp
Model Tuning: Random Forest: rf
Model Tuning: Random Forest: cforest (uses ctree algorithm)
Graphical User Interfaces (GUIs) for the R language help beginners get started learning R, help non-programmers get their work done, and help teams of programmers and non-programmers work together by turning code into menus and dialog boxes. There has been quite a lot of progress on R GUIs since my last post on this topic. Below I describe some of the features added to several R GUIs.
BlueSky Statistics
BlueSky Statistics has added mixed-effects linear models. Its dialog shows an improved model builder that will be rolled out to the other modeling dialogs in future releases. Other new statistical methods include quantile regression, survival analysis using both Kaplan-Meier and Cox Proportional Hazards models, Bland-Altman plots, Cohen’s Kappa, Intraclass Correlation, odds ratios and relative risk for M by 2 tables, and sixteen diagnostic measures such as sensitivity, specificity, PPV, NPV, Youden’s Index, and the like. The ability to create complex tables of statistics was added via the powerful arsenal package. Some examples of the types of tables you can create with it are shown here.
Several new dialogs have been added to the Data menu. The Compute Dummy Variables dialog creates dummy (aka indicator) variables from factors for use in modeling. That approach offers greater control over how the dummies are created than you would have when including factors directly in models.
A new Factor Levels menu item leads to many of the functions from the forcats package. They allow you to reorder factor levels by count, by occurrence in the dataset, by functions of another variable, allow you to lump low-frequency levels into a single “Other” category, and so on. These are all helpful in setting the order and nature of, for example, bars in a plot or entries in a table.
The BlueSky Data Grid now has icons that show the type of variable i.e. factor, ordered factor, string, numeric, date or logical. The Output Viewer adds icons to let you add notes to the output (not full R Markdown yet), and a trash can icon lets you delete blocks of output.
A comprehensive list of the changes to this release is located here and my updated review of it is here.
jamovi
New modules expand jamovi’s capabilities to include time-based survival analysis, Bland-Altman analysis & plots, behavioral change analysis, advanced mediation analysis, differential item analysis, and quantiles & probabilities from various continuous distributions.
jamovi’s new Flexplot module greatly expands the types of graphs it can create, letting you take a single graph type and repeat it in rows and/or columns making it easy to visualize how the data is changing across groups (called facet, panel, or lattice plots).
You can read more about Flexplot here, and my recently-updated review of jamovi is here.
JASP
The JASP package has added two major modules, machine learning, and network analysis. The machine learning module includes boosting, K-nearest neighbors, and random forests for both regression and classification problems. For regression, it also adds regularized linear regression. For clustering, it covers hierarchical, K-means, random forest, density-based, and fuzzy C-means methods. It can generate models and add predictions to your dataset, but it still cannot save models for future use. The main method it is missing is a single decision tree model. While less accurate predictors, a simple tree model can often provide insight that is lacking from other methods.
Another major addition to JASP is Network Analysis. It helps you to study the strengths of interactions among people, cell phones, etc. With so many people working from home during the Coronavirus pandemic, it would be interesting to see what this would reveal about how our patterns of working together have changed.
A really useful feature in JASP is its Data Library. It greatly speeds your ability to try out a new feature by offering a completely worked-out example including data. When trying out the network analysis feature, all I had to do was open the prepared example to see what type of data it would use. With most other data science software, you’re left to dig about in a collection of datasets looking for a good one to test a particular analysis. Nicely done!
I’ve updated my full review of JASP, which you can read here.
RKWard
The main improvement to the RKWard GUI for R is adding support for R Markdown. That makes it the second GUI to support R Markdown after R Commander. Both the jamovi and BlueSky teams are headed that way. RKWard’s new live preview feature lets you see text, graphics, and markdown as you work. A comprehensive list of new features is available here, and my full review of it is here.
Conclusion
R GUIs are gaining features at a rapid pace, quickly closing in on the capabilities of commercial data science packages such as SAS, SPSS, and Stata. I encourage R GUI users to contribute their own additions to the menus and dialog boxes of their favorite(s). The development teams are always happy to help with such contributions. To follow the progress of these and other R GUIs, subscribe to my blog, or follow me on twitter.
Data science is being used in many ways to improve healthcare and reduce costs. We have written a textbook, Introduction to Biomedical Data Science, to help healthcare professionals understand the topic and to work more effectively with data scientists. The textbook content and data exercises do not require programming skills or higher math. We introduce open source tools such as R and Python, as well as easy-to-use interfaces to them such as BlueSky Statistics, jamovi, R Commander, and Orange. Chapter exercises are based on healthcare data, and supplemental YouTube videos are available in most chapters.
For instructors, we provide PowerPoint slides for each chapter, exercises, quiz questions, and solutions. Instructors can download an electronic copy of the book, the Instructor Manual, and PowerPoints after first registering on the instructor page.
The book is available in print
and various electronic formats. Because it is self-published, we plan to update it more rapidly than would be
possible through traditional publishers.
Below you will find a detailed table of contents and a list
of the textbook authors.
Table of Contents
OVERVIEW OF BIOMEDICAL DATA SCIENCE
Introduction
Background and history
Conflicting perspectives
the statistician’s perspective
the machine learner’s perspective
the database administrator’s perspective
the data visualizer’s perspective
Data analytical processes
raw data
data pre-processing
exploratory data analysis (EDA)
predictive modeling approaches
types of models
types of software
Major types of analytics
descriptive analytics
diagnostic analytics
predictive analytics (modeling)
prescriptive analytics
putting it all together
Biomedical data science tools
Biomedical data science education
Biomedical data science careers
Importance of soft skills in data science
Biomedical data science resources
Biomedical data science challenges
Future trends
Conclusion
References
SPREADSHEET TOOLS AND TIPS
Introduction
basic spreadsheet functions
download the sample spreadsheet
Navigating the worksheet
Clinical application of spreadsheets
formulas and functions
filter
sorting data
freezing panes
conditional formatting
pivot tables
visualization
data analysis
Tips and tricks
Microsoft Excel shortcuts – windows users
Google sheets tips and tricks
Conclusions
Exercises
References
BIOSTATISTICS PRIMER
Introduction
Measures of central tendency & dispersion
the normal and log-normal distributions
Descriptive and inferential statistics
Categorical data analysis
Diagnostic tests
Bayes’ theorem
Types of research studies
observational studies
interventional studies
meta-analysis
orrelation
Linear regression
Comparing two groups
the independent-samples t-test
the wilcoxon-mann-whitney test
Comparing more than two groups
Other types of tests
generalized tests
exact or permutation tests
bootstrap or resampling tests
Stats packages and online calculators
commercial packages
non-commercial or open source packages
online calculators
Challenges
Future trends
Conclusion
Exercises
References
DATA VISUALIZATION
Introduction
historical data visualizations
visualization frameworks
Visualization basics
Data visualization software
Microsoft Excel
Google sheets
Tableau
R programming language
other visualization programs
Visualization options
visualizing categorical data
visualizing continuous data
Dashboards
Geographic maps
Challenges
Conclusion
Exercises
References
INTRODUCTION TO DATABASES
Introduction
Definitions
A brief history of database models
hierarchical model
network model
relational model
Relational database structure
Clinical data warehouses (CDWs)
Structured query language (SQL)
Learning SQL
Conclusion
Exercises
References
BIG DATA
Introduction
The seven v’s of big data related to health care data
Technical background
Application
Challenges
technical
organizational
legal
translational
Future trends
Conclusion
References
BIOINFORMATICS and PRECISION MEDICINE
Introduction
History
Definitions
Biological data analysis – from data to discovery
Biological data types
genomics
transcriptomics
proteomics
bioinformatics data in public repositories
biomedical cancer data portals
Tools for analyzing bioinformatics data
command line tools
web-based tools
Genomic data analysis
Genomic data analysis workflow
variant calling pipeline for whole exome sequencing data
quality check
alignment
variant calling
variant filtering and annotation
downstream analysis
reporting and visualization
Precision medicine – from big data to patient care
Examples of precision medicine
Challenges
Future trends
Useful resources
Conclusion
Exercises
References
PROGRAMMING LANGUAGES FOR DATA ANALYSIS
Introduction
History
R language
installing R & rstudio
an example R program
getting help in R
user interfaces for R
R’s default user interface: rgui
Rstudio
menu & dialog guis
some popular R guis
R graphical user interface comparison
R resources
Python language
installing Python
an example Python program
getting help in Python
user interfaces for Python
reproducibility
R vs. Python
Future trends
Conclusion
Exercises
References
MACHINE LEARNING
Brief history
Introduction
data refresher
training vs test data
bias and variance
supervised and unsupervised learning
Common machine learning algorithms
Supervised learning
Unsupervised learning
dimensionality reduction
reinforcement learning
semi-supervised learning
Evaluation of predictive analytical performance
classification model evaluation
regression model evaluation
Machine learning software
Weka
Orange
Rapidminer studio
KNIME
Google TensorFlow
honorable mention
summary
Programming languages and machine learning
Machine learning challenges
Machine learning examples
example 1 classification
example 2 regression
example 3 clustering
example 4 association rules
Conclusion
Exercises
References
ARTIFICIAL INTELLIGENCE
Introduction
definitions
History
Ai architectures
Deep learning
Image analysis (computer vision)
Radiology
Ophthalmology
Dermatology
Pathology
Cardiology
Neurology
Wearable devices
Image libraries and packages
Natural language processing
NLP libraries and packages
Text mining and medicine
Speech recognition
Electronic health record data and AI
Genomic analysis
AI platforms
deep learning platforms and programs
Artificial intelligence challenges
General
Data issues
Technical
Socio economic and legal
Regulatory
Adverse unintended consequences
Need for more ML and AI education
Future trends
Conclusion
Exercises
References
Authors
Brenda Griffith Technical Writer Data.World Austin, TX
Robert Hoyt MD, FACP, ABPM-CI, FAMIA Associate Clinical Professor Department of Internal Medicine Virginia Commonwealth University Richmond, VA
David Hurwitz MD, FACP, ABPM-CI Associate CMIO Allscripts Healthcare Solutions Chicago, IL
Madhurima Kaushal MS Bioinformatics Washington University at St. Louis, School of Medicine St. Louis, MO
Robert Leviton MD, MPH, FACEP, ABPM-CI, FAMIA Assistant Professor New York Medical College Department of Emergency Medicine Valhalla, NY
Karen A. Monsen PhD, RN, FAMIA, FAAN Professor School of Nursing University of Minnesota Minneapolis, MN
Robert Muenchen MS, PSTAT Manager, Research Computing Support University of Tennessee Knoxville, TN
Dallas Snider PhD Chair, Department of Information Technology University of West Florida Pensacola, FL
A special thanks to Ann Yoshihashi MD for her help with the publication of this textbook.
R AnalyticFlow (RAF) is a free and open source graphical user interface (GUI) for the R language that focuses on beginners looking to point-and-click their way through analyses. What sets it apart from the other half-dozen GUIs for R is that it uses a flowchart-like workflow diagram to control the analysis instead of only menus. In my first programming class back in the Pleistocene Era, my professor told us to never begin a program without doing a flowchart of what you were trying to accomplish. With workflow tools, you get the benefit of the diagram outlining the big picture, while the dialog box settings in each node control what happens at each step. In Figure 1 you can get a good idea of what is happening without any further information.
Another advantage you get with most workflow tools is the ability to reuse workflows very easily because the dataset is read in only once at the beginning. Unfortunately, most of that advantage is missing from R AnalyticFlow (hereafter, “RAF”) since you must specify which dataset is used in every node. The downside to workflow tools is that they’re slightly harder to learn than menu-based systems. This involves learning how to draw a diagram, what flows through it (e.g. datasets, models), and how to generate a single comprehensive reports for the entire analysis.
This post is one of a series of comparative reviews which aim to help non-programmers choose the GUI that is best for them. The reviews all follow a standard template to make comparisons across products easier. These reviews also include a cursory description of the programming support that each GUI offers.
Figure 1. An example workflow from R AnalyticFlow.
Terminology
There are various definitions of user interface types, so here’s how I’ll be using these terms:
GUI = Graphical User Interface using menus and dialog boxes to avoid having to type programming code. I do not include any assistance for programming in this definition. So, GUI users are people who prefer using a GUI to perform their analyses. They don’t have the time or inclination to become good programmers.
IDE = Integrated Development Environment which helps programmers write code. I do not include point-and-click style menus and dialog boxes when using this term. IDE users are people who prefer to write R code to perform their analyses.
Installation
The various user interfaces available for R differ quite a lot in how they’re installed. Some, such as BlueSky Statistics, jamovi, and RKWard, install in a single step. Others, such as Deducer, install in multiple steps (up to seven steps, depending on your needs). Advanced computer users often don’t appreciate how lost beginners can become while attempting even a simple installation. The Help Desks at most universities are flooded with such calls at the beginning of each semester!
RAF is available for Mac, and Linux. Its installation takes four steps:
Install Java, if you don’t already have it installed. This can be tricky as you must match the type of Java to the type of R you use. Most computers these days have 64-bit operating systems. Whether 32-bit or 64-bit, you must use the same “bitness” on all of these steps, or it will not work.
Next, install R if you haven’t already (available here).
Install RAF itself after downloading it from here.
Start RAF. It will prompt you to install some R packages, notably rJava. This step requires Internet access. To install if you don’t have such access, see the RAF website’s About R Packages section for important details on how to proceed (from another machine that does have Internet access, of course).
Plug-in Modules
When choosing a GUI, one of the most fundamental questions is: what can it do for you? What the initial software installation of each GUI gets you is covered in the Graphics, Analysis, and Modeling sections of this series of articles. Regardless of what comes built-in, it’s good to know how active the development community is. They contribute “plug-ins” which add new menus and dialog boxes to the GUI. This level of activity ranges from very low (RKWard, Deducer) through moderate (jamovi) to very active (R Commander).
RAF does not offer any plug-in modules, though its developers do provide instruction on how you can create your own.
Startup
Some user interfaces for R, such as BlueSky and jamovi, start by double-clicking on a single icon, which is great for people who prefer to not write code. Others, such as R Commander and JGR, have you start R, then load a package from your library, and then call a function. That’s better for people looking to learn R, as those are among the first tasks they’ll have to learn anyway.
You start RAF directly by double-clicking its icon from your desktop or choosing it from your Start Menu (i.e. not from within R itself). On my system, I had to right-click the icon and choose, “Run as Administrator” or I would get the message, “Failed to Launch R. Confirm Settings?” If I responded “Yes”, it showed the path to my installation of R, which was already correct. I tried a second computer and it did start, but when it tried to install the JavaGD and rJava packages, it said, “Warning in install.packages (c(“JavaGD”,”rJava”)) : ‘lib = “C:/Program Files/R/R-3.6.1/library” ‘ is not writable. Would you like to use a personal library instead?”
Upon startup, it displays its startup screen, shown in Figure 2. Quick Start puts you into the software with a new Flow window open. New Project starts a new workflow, and Bookmarks give you quick access to existing workflows.
Figure 2. R AnalyticFlow’s Startup Screen.
Data Editor
A data editor is a fundamental feature in data analysis software. It puts you in touch with your data and lets you get a feel for it, if only in a rough way. A data editor is such a simple concept that you might think there would be hardly any differences in how they work in different GUIs. While there are technical differences, to a beginner what matters the most are the differences in simplicity. Some GUIs, including jamovi, let you create only what R calls a data frame. They use more common terminology and call it a data set: you create one, you save one, later you open one, then you use one. Others, such as RKWard trade this simplicity for the full R language perspective: a data set is stored in a workspace. So the process goes: you create a data set, you save a workspace, you open a workspace, and choose a data set from within it.
To start entering data, choose “Input> Enter Data” and drag the selection onto the workflow editor window. An empty spreadsheet will appear (Figure 3). You can enter variable names on the first line if you check the “Header: Use 1st Row” box at the bottom of the window. This is the first hint you’ll see that RAF leans on R terminology that can be somewhat esoteric. RAF’s developers could have labeled this choice as “Column Names” but went with the R terminology of “Header” instead. This approach may be confusing for beginners, but if their goal is to learn R, it will help in the long run.
To enter factors (R’s categorical variables), choose the “Options” tab and check, “Convert Characters to Factors”, then RAF will convert the character string variables you enter to factors. Otherwise, it will leave them as characters. Dates remain stored as characters; you have to use “Processing> Set Data Type” node to change them, and they must be entered in the form yyyy-mm-dd.
Figure 3. R Analytic Flow’s data entry screen.
There is no limit to the number of rows and columns you can enter initially. However, once you choose “Run”, the data frame is created and can no longer be edited!
Saving the workflow is done with the standard “File > Save As” menu. You must save each one to its own file. To save the flow and the various objects that it uses such as data frames and models, use “Project > Export”. When receiving a project from a colleague, use “Project> Import” to begin using it.
Data Import
To analyze data, you must first read it. While many R GUIs can import a wide range of data formats such as files created by other statistics programs and databases, RAF can import only text and R objects.
RAF’s text import feature is well done. Once you select an Input File, it quickly scans the file and figures out if variable names are present, the delimiters it uses to separate the columns, and so on. It then displays a “preview” (Figure 4, bottom). It does this quickly since its preview is only on the first 100 rows of data. If the preview displays errors, you then manually change the settings and check the preview until it’s correct. When the preview looks good, you click, “Run”, it will then read all the data.
Figure 4. The Read Text File window.
Data Export
The ability to export data to a wide range of file types helps when you, or other members of your research team, have to use multiple tools to complete a task. Unfortunately, this is a very weak area for R GUIs. Deducer offers no data export at all, and R Commander, and rattle can export only delimited text files (an earlier version of this listed jamovi as having very limited data export; that has now been expanded). Only BlueSky offers a fairly comprehensive set of export options. Unfortunately, RAF falls into the former group, being able only to export data in text and R object files.
Data Management
It’s often said that 80% of data analysis time is spent preparing the data. Variables need to be transformed, recoded, or created; strings and dates need to be manipulated; missing values need to be handled; datasets need to be stacked or merged, aggregated, transposed, or reshaped (e.g. from wide to long and back). A critically important aspect of data management is the ability to transform many variables at once. For example, social scientists need to recode many survey items, biologists need to take the logarithms of many variables. Doing these types of tasks one variable at a time can be tedious. Some GUIs, such as jamovi and RKWard handle only a few of these functions. Others, such as BlueSky and the R Commander, can handle many, but not all, of them.
RAF handles a fairly basic set of data management tools:
Add/Edit Columns
Rename – Variables in a data frame)
Set Data Type
Select Rows
Select Columns
Missing Values – Sets values as missing, no imputation)
Sort
Sampling
Aggregate
Merge – Various joins
Merge – Adds rows
Manage Objects (copies, deletes, renames)
Workflows, Menus & Dialog Boxes
The goal of pointing & clicking your way through an analysis is to save time by recognizing dialog box settings rather than performing the more difficult task of recalling programming commands. Some GUIs, such as BlueSky and jamovi, make this easy by sticking to menu standards and using simpler dialog boxes; others, such as RKWard, use non-standard menus that are unique to it and hence require more learning.
RAF uses a unique interface. There are two ways to add build a workflow that guides your analysis. First, you can click on a toolbar icon, which drops down a menu. Click on a selection, and – without releasing the mouse button – drag your selection onto the flow window. In that case, the dialog box with its options opens below the flow area (Figure 3, bottom right).
The second way to use it is to click on a toolbar icon, drop down its menu, click on a selection and immediately release the mouse button. This causes the dialog box to appear floating in the middle of the screen (not shown). When you finish choosing your settings, there is a “Drag to Add” button at the top of the dialog. Clicking that button causes the dialog box to collapse into an icon which you can then drag onto the workflow surface.
Regardless of which method you choose, if you drop the new icon onto the top of one that is already in the workflow, it will move the new icon to the right and draw an arrow (called an “edge”) connecting the older one to the new. If you don’t drop it onto an icon that’s already in your workflow, you can add a connecting arrow later by clicking on the first icon, then choose “Draw Edge” and an arrow will appear aimed to the right (workflows go mostly left to right). The arrow will float around as you move your mouse, until you click on the second icon. A third way to connect the nodes in a flow is to click one icon, hold the Alt key down, then drag to the second icon.
Figure 3 shows the entire RAF window. On the top right is the workflow. Here are the steps I followed to create it:
I chose “Input> Read Text File” and dragged it onto the workflow. The icon’s settings appeared in the bottom right window.
I filled in the dialog box’s settings, then clicked “Run”. It named the icon after the file mydata.csv and a spreadsheet appeared in the upper-right.
I chose “Statistics> Cross Tabulation”, and dragged its icon onto the data icon.
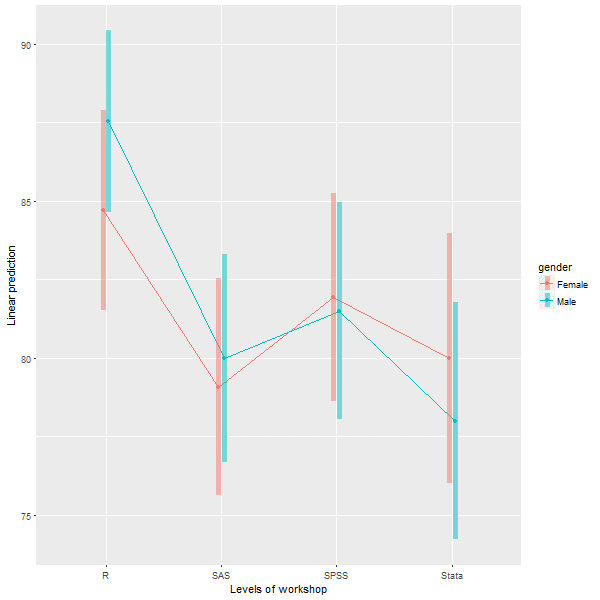
I clicked the downward-facing arrow in the “Group By” box, and chose the variables. The first one I chose (workshop) formed the rows and the second (gender) formed the columns. Unlike most GUIs, there’s no indication of row and column roles.
I clicked “Run Node” at the top of the cross tabulation dialog box. The cross tabulation output appeared in the upper left window (right half). The code that RAF wrote to perform the task appears in the R Console window in the lower left.
You can run an entire flow by clicking “Run Flow” at the top left of the Flow window. While describing the process of building a workflow is tedious, learning to build one is quite easy to learn.
Figure 3. The entire R Analytic Flow window, with Cross Tabulation highlighted. In the top row are the viewer window (left) and flow window (right). In the bottom row are the R console (left) and the dialog box for the chosen icon (right). The Cross Tabulation icon is selected, so its dialog box is shown.
The goal of using a GUI is to make analysis easy, so GUI dialog boxes are usually quite simple to use and include everything that’s relevant within a single box. I looked at all the options in this dialog but could not find one to do a very common test for such a cross-tabulation table: the chi-squared test. RAF uses an aspect of R objects that ends up essentially creating two different types of dialog boxes in separate parts of its interface. R objects contain multiple bits of output. You can display them using generic R functions such as summary() and print(). The output window has radio buttons for those functions (Figure 3, right above the cross-tabulation table). Clicking the “summary” button will call R’s summary() function to display the chi-squared results where the table is currently shown. To study the pattern in the table and the chi-squared results requires clicking back and forth on Table and summary; you can’t get them to both appear on your screen at the same time.
Correlations provide another example. The statistics are shown, but their p-values are not shown until you click on the “summary” button. This approach is confusing for beginners, but good for people wishing to learn R.
A common data analysis task is repeating the same analysis across many variables. For example, you might want to repeat the above cross tabulation (or t-tests, etc.) on many variables at once. This is usually quite easy to accomplish in most GUIs, but not in RAF. Since R’s functions may not offer that ability without using R’s “apply” family of functions (or loops), and RAF does not support such functions, such simple tasks become quite a lot of work when using RAF. You need to add an node to your flow for each and every variable!
Each dialog box has an “Advanced” tab which allows you to enter the name of any R argument(s) in one column, and any value(s) you would like to pass to that argument in another. That’s a nice way to offer graphical control over common tasks, while assuring that every task a function is capable of is still available.
In a complex analysis, workflows can become quite complex and hard to read. A solution to this problem is the concept of a “metanode”. Metanodes allow you t take an entire section of your workflow and collapse it into what appears to be a single node. For example, you might commonly use eight nodes to prepare a dataset for analysis. You could combine all eight into a new node you call “Data Prep”, greatly simplifying the workflow. Unfortunately, RAF does not offer metanodes, as do other workflow-driven data science tools such as KNIME and RapidMiner.
One of the most surprising aspects of RAF’s workflow style is that every node specifies its input and output objects. That means that you can run any analysis with no connecting arrows in your diagram! Rather than be a required feature as with many workflow-based tools, in RAF they offer only the convenience of re-running an entire flow at once.
During GUI-driven analysis, the fact that R is doing the work is quite obvious as the code and any resulting messages appear in the Console window.
Documentation & Training
The only written documentation for RAF is the brief, but easy to follow, R AnalyticFlow 3 Starter Guide. Kamala Valarie has also done a 15-minute video on YouTube showing how to use RAF.
Help
R GUIs provide simple task-by-task dialog boxes that generate much more complex code. So for a particular task, you might want to get help on 1) the dialog box’s settings, 2) the custom functions it uses (if any), and 3) the R functions that the custom functions use. Nearly all R GUIs provide all three levels of help when needed. The notable exception is the R Commander, which lacks help on the dialog boxes themselves.
The level of help that RAF offers is only the built-in R help file for the particular function you’re using. However, I had problems with the help getting stuck and showing me the help file from previous tasks rather than the one I was currently using.
Graphics
The various GUIs available for R handle graphics in several ways. Some, such as R Commander and RKWard, focus on R’s built-in graphics. Others, such as BlueSky Statistics use the popular ggplot2 package. Still others, such as jamovi, use their own functions and integrate them into analysis steps.
GUIs also differ quite a lot in how they control the style of the graphs they generate. Ideally, you could set the style once, and then all graphs would follow it. That’s how BlueSky and jamovi work.
RAF uses the very flexible lattice package for all of its graphics. That makes it particularly easy to display “small multiples” of the same plot repeated by levels of another variable or two. There does not appear to be any way to control the style of the plots.
It has been only two months since I summarized my reviews of point-and-click front ends for R, and it’s already out of date! I have converted that post into a regularly-updated article and added a plot of total features, which I repeat below. It shows the total number of features in each package, including the latest versions of BlueSky Statistics, JASP, and jamovi. The reviews which initially appeared as blog posts are now regularly-updated pages.
New Features in JASP
Let’s take a look at some of the new features, starting with the version of JASP that was released three hours ago:
Interface adjustments
Data panel, analysis input panel and results panel can be manipulated much more intuitively with sliders and show/hide buttons
Changed the analysis input panel to have an overview of all opened analyses and added the possibility to change titles, to show documentation, and remove analyses
Enhanced the navigation through the file menu; it is now possible to use arrow keys or simply hover over the buttons
Added possibility to scale the entire application with Ctrl +, Ctrl – and Ctrl 0
Added MANOVA
Added Confirmatory Factor Analysis
Added Bayesian Multinomial Test
Included additional menu preferences to customize JASP to your needs
Added/updated help files for most analyses
R engine updated from 3.4.4 to 3.5.2
Added Šidák correction for post-hoc tests (AN(C)OVA)
A complete list of fixes and features is available here. JASP is available for free from their download page. My comparative review of JASP is here.
New Features in jamovi
Two of the usability features added to jamovi recently are templates and multi-file input. Both are described in detail here.
Templates enable you to save all the steps in your work as a template file. Opening that file in jamovi then lets you open a new dataset and the template will recreate all the previous analyses and graphs using the new data. It provides reusability without having to depend on the R code that GUI users are trying to avoid using.
The multi-file input lets you select many CSV files at once and jamovi will open and stack them all (they must contain common variable names, of course).
Other new analytic features have been added with a set of modeling modules. They’re described in detail here, and a list of some of their capability is below. You can read my full review of jamovi here, and you can download it for free here.
OLS Regression (GLM)
OLS ANOVA (GLM)
OLS ANCOVA (GLM)
Random coefficients regression (Mixed)
Random coefficients ANOVA-ANCOVA (Mixed)
Logistic regression (GZLM)
Logistic ANOVA-like model (GZLM)
Probit regression (GZLM)
Probit ANOVA-like model (GZLM)
Multinomial regression (GZLM)
Multinomial ANOVA-like model (GZLM)
Poisson regression (GZLM)
Poisson ANOVA-like model (GZLM)
Overdispersed Poisson regression (GZLM)
Overdispersed Poisson ANOVA-like model (GZLM)
Negative binomial regression (GZLM)
Negative binomial ANOVA-like model (GZLM)
Continuous and categorical independent variables
Omnibus tests and parameter estimates
Confidence intervals
Simple slopes analysis
Simple effects
Post-hoc tests
Plots for up to three-way interactions for both categorical and continuous independent variables.
Automatic selection of best estimation methods and degrees of freedom selection
Type III estimation
New Features in BlueSky Statistics
The BlueSky developers have been working on adding psychometric methods (for a book that is due out soon) and support for distributions. My full review is here and you can download BlueSky Statistics for free here.
Model Fitting: IRT: Simple Rasch Model
Model Fitting: IRT: Simple Rasch Model (Multi-Faceted)
Model Fitting: IRT: Partial Credit Model
Model Fitting: IRT: Partial Credit Model (Multi-Faceted)
Model Fitting: IRT: Rating Scale Model
Model Fitting: IRT: Rating Scale Model (Multi-Faceted)
Model Statistics: IRT: ICC Plots
Model Statistics: IRT: Item Fit
Model Statistics: IRT: Plot PI Map
Model Statistics: IRT: Item and Test Information
Model Statistics: IRT: Likelihood Ratio and Beta plots
Model Statistics: IRT: Personfit
Distributions: Continuous: BetaProbabilities
Distributions: Continuous: Beta Quantiles
Distributions: Continuous: Plot Beta Distribution
Distributions: Continuous: Sample from Beta Distribution
Distributions: Continuous: Cauchy Probabilities
Distributions: Continuous: Plot Cauchy Distribution
Distributions: Continuous: Cauchy Quantiles
Distributions: Continuous: Sample from Cauchy Distribution
Distributions: Continuous: Sample from Cauchy Distribution
Now that I’ve completed seven detailed reviews of Graphical User Interfaces (GUIs) for R, let’s compare them. It’s easy enough to count their features and plot them, so let’s start there. I’m basing the counts on the number of menu items in each category. That’s not too hard to get, but it’s far from perfect. Some software has fewer menu choices, depending instead on dialog box choices. Studying every menu and dialog box would be too time-consuming, so be aware of this limitation. I’m putting the details of each measure in the appendixso you can adjust the figures and create your own graphs. If you decide to make your own graphs, I’d love to hear from you in the comments below.
Figure 1 shows the number of analytic methods each software supports on the x-axis and the number of graphics methods on the y-axis. The analytic methods count combines statistical features, machine learning / artificial intelligence ones (ML/AI), and the ability to create R model objects. The graphics features count totals up the number of bar charts, scatterplots, etc. each package can create.
The ideal place to be in this graph is in the upper right corner. We see that BlueSky and R Commander offer quite a lot of both analytic and graphical features. Rattle stands out as having the second greatest number of graphics features. JASP is the lowest on graphics features and 3rd from the bottom on analytic ones.
Next, let’s swap out the y-axis for general usability features. These consist of a variety of features that make your work easier, including data management capabilities (see appendix for details).
Figure 2 shows that BlueSky and R Commander still in the top two positions overall, but now Deducer has nearly caught up with R Commander on the number of general features. That’s due to its reasonably strong set of data management tools, plus its output is in true word processing tables saving you the trouble of formatting it yourself. Rattle is much lower in this plot since, while its graphics capabilities are strong (at least in relation to ML/AI tasks), it has minimal data management capabilities.
These plots help show us three main overall feature sets, but each package offers things that the others don’t. Let’s look at a brief overview of each. Remember that each of these has a detailed review that follows my standard template. I’ll start with the two that have come out on top, then follow in alphabetical order.
The R Commander – This is the oldest GUI, having been around since at least 2005. There are an impressive 41 plug-ins developed for it. It is currently the only R GUI that saves R Markdown files, but it does not create word processing tables by default, as some of the others do. The R code it writes is classic, rarely using the newer tidyverse functions. It works as a partner to R; you install R separately, then use it to install and start R Commander. It makes it easy to blend menu-based analysis with coding. If your goal is to learn to code in classic R, this is an excellent choice.
BlueSky Statistics – This software was created by former SPSS employees and it shares many of SPSS’ features. BlueSky is only a few years old, and it converted from commercial to open source just a few months ago. Although BlueSky and R Commander offer many of the same features, they do them in different ways. When using BlueSky, it’s not initially apparent that R is involved at all. Unless you click the “Syntax” button that every dialog box has, you’ll never see the R code or the code editor. Its output is in publication-quality tables which follow the popular style of the American Psychological Association.
Deducer – This has a very nice-looking interface, and it’s probably the first to offer true word processing tables by default. Being able to just cut and paste a table into your word processor saves a lot of time and it’s a feature that has been copied by several others. Deducer was released in 2008, and when I first saw it, I thought it would quickly gain developers. It got a few, but development seems to have halted. Deducer’s installation is quite complex, and it depends on the troublesome Java software. It also used JGR, which never became as popular as the similar RStudio. The main developer, Ian Fellows, has moved on to another very interesting GUI project called Vivid.
jamovi– The developers who form the core of the jamovi project used to be part of the JASP team. Despite the fact that they started a couple of years later, they’re ahead of JASP in several ways at the moment. Its developers decided that the R code it used should be visible and any R code should be executable, something that differentiated it from JASP. jamovi has an extremely interactive interface that shows you the result of every selection in each dialog box. It also saves the settings in every dialog box, and lets you re-use every step on a new dataset by saving a “template.” That’s extremely useful since GUI users often don’t want to learn R code. jamovi’s biggest weakness its dearth of data management tasks, though there are plans to address that.
JASP– The biggest advantage JASP offers is its emphasis on Bayesian analysis. If that’s your preference, this might be the one for you. At the moment JASP is very different from all the other GUIs reviewed here because it won’t show you the R code it’s writing, and you can’t execute your own R code from within it. Plus the software has not been open to outside developers. The development team plans to address those issues, and their deep pockets should give them an edge.
Rattle– If your work involves ML/AI (a.k.a. data mining) instead of standard statistical methods, Rattle may be the best GUI for you. It’s focused on ML/AI, and its tabbed-based interface makes quick work of it. However, it’s the weakest of them all when it comes to statistical analysis. It also lacks many standard data management features. The only other GUI that offers many ML/AI features is BlueSky.
RKWard– This GUI blends a nice point-and-click interface with an integrated development environment that is the most advanced of all the other GUIs reviewed here. It’s easy to install and start, and it saves all your dialog box settings, allowing you to rerun them. However, that’s done step-by-step, not all at once as jamovi’s templates allow. The code RKWard creates is classic R, with no tidyverse at all.
Conclusion
I hope this brief comparison will help you choose the R GUI that is right for you. Each offers unique features that can make life easier for non-programmers. If one catches your eye, don’t forget to read the full review of it here.
Acknowledgements
Writing this set of reviews has been a monumental undertaking. It would not have been possible without the assistance of Bruno Boutin, Anil Dabral, Ian Fellows, John Fox, Thomas Friedrichsmeier, Rachel Ladd, Jonathan Love, Ruben Ortiz, Christina Peterson, Josh Price, Eric-Jan Wagenmakers, and Graham Williams.
Appendix: Guide to Scoring
In figures 1 and 2, Analytic Features adds up: statistics, machine learning / artificial intelligence, the ability to create R model objects, and the ability to validate models using techniques such as k-fold cross-validation. The Graphics Features is the sum of two rows, the number of graphs the software can create plus one point for small multiples, or facets, if it can do them. Usability is everything else, with each row worth 1 point, except where noted.
Feature
Definition
Simple installation
Is it done in one step?
Simple start-up
Does it start on its own without starting R, loading packages, etc.?
Import Data Files
How many files types can it import?
Import Database
How many databases can it read from?
Export Data Files
How many file formats can it write to?
Data Editor
Does it have a data editor?
Can work on >1 file
Can it work on more than one file at a time?
Variable View
Does it show metadata in a variable view, allowing for many fast edits to metadata?
Data Management
How many data management tasks can it do?
Transform Many
Can it transform many variables at once?
Graph Types
How many graph types does it have?
Small Multiples
Can it show small multiples (facets)?
Model Objects
Can it create R model objects?
Statistics
How many statistical methods does it have?
ML/AI
How many ML / AI methods does it have?
Model Validation
Does it offer model validation (k-fold, etc.)?
R Code IDE
Can you edit and execute R code?
GUI Reuse
Does it let you re-use work without code?
Code Reuse
Does it let you rerun all using code?
Package Management
Does it manage packages for you?
Table of Contents
Does output have a table of contents?
Re-order
Can you re-order output?
Publication Quality
Is output in publication quality by default?
R Markdown
Can it create R Markdown?
Add comments
Can you add comments to output?
Group-by
Does it do group-by repetition of any other task?
Output as Input
Does it save equivalent to broom’s tidy, glance, augment? (They earn 1 point for each)
JASP is a free and open source statistics package that targets beginners looking to point-and-click their way through analyses. This article is one of a series of reviews which aim to help non-programmers choose the Graphical User Interface (GUI) for R, which best meets their needs. Most of these reviews also include cursory descriptions of the programming support that each GUI offers.
JASP stands for Jeffreys’ Amazing Statistics Program, a nod to the Bayesian statistician, Sir Harold Jeffreys. It is available for Windows, Mac, Linux, and there is even a cloud version. One of JASP’s key features is its emphasis on Bayesian analysis. Most statistics software emphasizes a more traditional frequentist approach; JASP offers both. However, while JASP uses R to do some of its calculations, it does not currently show you the R code it uses, nor does it allow you to execute your own. The developers hope to add that to a future version. Some of JASP’s calculations are done in C++, so getting that converted to R will be a necessary first step on that path.
Figure 1. JASP’s main screen.
Terminology
There are various definitions of user interface types, so here’s how I’ll be using these terms:
GUI = Graphical User Interface using menus and dialog boxes to avoid having to type programming code. I do not include any assistance for programming in this definition. So, GUI users are people who prefer using a GUI to perform their analyses. They don’t have the time or inclination to become good programmers.
IDE = Integrated Development Environment which helps programmers write code. I do not include point-and-click style menus and dialog boxes when using this term. IDE users are people who prefer to write R code to perform their analyses.
Installation
The various user interfaces available for R differ quite a lot in how they’re installed. Some, such as BlueSky Statistics, jamovi, and RKWard, install in a single step. Others install in multiple steps, such as R Commander (two steps), and Deducer (up to seven steps). Advanced computer users often don’t appreciate how lost beginners can become while attempting even a simple installation. The HelpDesks at most universities are flooded with such calls at the beginning of each semester!
JASP’s single-step installation is extremely easy and includes its own copy of R. So if you already have a copy of R installed, you’ll have two after installing JASP. That’s a good idea though, as it guarantees compatibility with the version of R that it uses, plus a standard R installation by itself is harder than JASP’s.
Plug-in Modules
When choosing a GUI, one of the most fundamental questions is: what can it do for you? What the initial software installation of each GUI gets you is covered in the Graphics, Analysis, and Modeling sections of this series of articles. Regardless of what comes built-in, it’s good to know how active the development community is. They contribute “plug-ins” which add new menus and dialog boxes to the GUI. This level of activity ranges from very low (RKWard, Deducer) to very high (R Commander).
For JASP, plug-ins are called “modules” and they are found by clicking the “+” sign at the top of its main screen. That causes a new menu item to appear. However, unlike most other software, the menu additions are not saved when you exit JASP; you must add them every time you wish to use them.
JASP’s modules are currently included with the software’s main download. However, future versions will store them in their own repository rather than on the Comprehensive R Archive Network (CRAN) where R and most of its packages are found. This makes locating and installing JASP modules especially easy.
Currently there are only four add-on modules for JASP:
Summary Stats – provides variations on the methods included in the Common menu
SEM – Structural Equation Modeling using lavaan (this is actually more of a window in which you type R code than a GUI dialog)
Meta Analysis
Network Analysis
Three modules are currently in development: Machine Learning, Circular analyses, and Auditing.
Startup
Some user interfaces for R, such as BlueSky, jamovi, and Rkward, start by double-clicking on a single icon, which is great for people who prefer to not write code. Others, such as R commander and Deducer, have you start R, then load a package from your library, and then call a function to finally activate the GUI. That’s more appropriate for people looking to learn R, as those are among the first tasks they’ll have to learn anyway.
You start JASP directly by double-clicking its icon from your desktop, or choosing it from your Start Menu (i.e. not from within R itself). It interacts with R in the background; you never need to be aware that R is running.
Data Editor
A data editor is a fundamental feature in data analysis software. It puts you in touch with your data and lets you get a feel for it, if only in a rough way. A data editor is such a simple concept that you might think there would be hardly any differences in how they work in different GUIs. While there are technical differences, to a beginner what matters the most are the differences in simplicity. Some GUIs, including BlueSky and jamovi, let you create only what R calls a data frame. They use more common terminology and call it a data set: you create one, you save one, later you open one, then you use one. Others, such as RKWard trade this simplicity for the full R language perspective: a data set is stored in a workspace. So the process goes: you create a data set, you save a workspace, you open a workspace, and choose a dataset from within it.
JASP is the only program in this set of reviews that lacks a data editor. It has only a data viewer (Figure 2, left). If you point to a cell, a message pops up to say, “double-click to edit data” and doing so will transfer the data to another program where you can edit it. You can choose which program will be used to edit your data in the “Preferences>Data Editing” tab, located under the “hamburger” menu in the upper-right corner. The default is Excel.
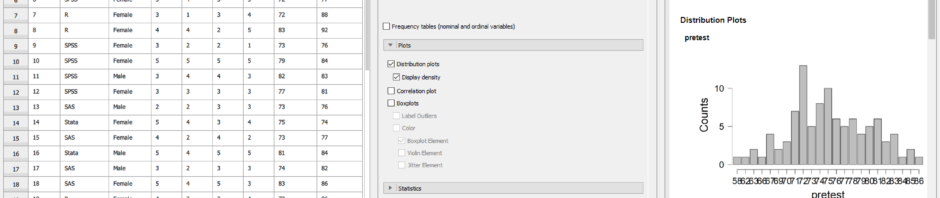
When JASP opens a data file, it automatically assigns metadata to the variables. As you can see in Figure 2, it has decided my variable “pretest” was a factor and provided a bar chart showing the counts of every value. For the extremely similar “posttest” variable it decided it was numeric, so it binned the values and provided a more appropriate histogram.
While JASP lacks the ability to edit data directly, it does allow you to edit some of the metadata, such as variable scale and variable (factor levels). I fixed the problem described above by clicking on the icon to the left of each variable name, and changing it from a Venn diagram representing “nominal”, to a ruler for “scale”. Note the use of terminology here, which is statistical rather than based on R’s use of “factor” and “numeric” abxyxas respectively. Teaching R is not part of JASP’s mission.
JASP cannot handle date/time variables other than to read them as character and convert them to factor. Once JASP decides a character or date/time variable is a factor, it cannot be changed.
Clicking on the name of a factor will open a small window on the top of the data viewer where you can over-write the existing labels. Variable names however, cannot be changed without going back to Excel, or whatever editor you used to enter the data.
Figure 2. The JASP data viewer is shown on the left-hand side.
Data Import
The ability to import data from a wide variety of formats is extremely important; you can’t analyze what you can’t access. Most of the GUIs evaluated in this series can open a wide range of file types and even pull data from relational databases. JASP can’t read data from databases, but it can import the following file formats:
Comma Separated Values (.csv)
Plain text files (.txt)
SPSS (.sav, but not .zsav, .por)
Open Document Spreadsheet (.ods)
The ability to read SAS and Stata files is planned for a future release. Though based on R, JASP cannot read R data files!
Data Export
The ability to export data to a wide range of file types helps when you need multiple tools to complete a task. Research is commonly a team effort, and in my experience, it’s rare to have all team members prefer to use the same tools. For these reasons, GUIs such as BlueSky, Deducer, and jamovi offer many export formats. Others, such as R Commander and RKward can create only delimited text files.
A fairly unique feature of JASP is that it doesn’t save just a dataset, but instead it saves the combination of a dataset plus its associated analyses. To save just the dataset, you go to the “File” tab and choose “Export data.” The only export format is comma separated value file (.csv).
Data Management
It’s often said that 80% of data analysis time is spent preparing the data. Variables need to be computed, transformed, scaled, recoded, or binned; strings and dates need to be manipulated; missing values need to be handled; datasets need to be sorted, stacked, merged, aggregated, transposed, or reshaped (e.g. from “wide” format to “long” and back).
A critically important aspect of data management is the ability to transform many variables at once. For example, social scientists need to recode many survey items, biologists need to take the logarithms of many variables. Doing these types of tasks one variable at a time is tedious.
Some GUIs, such as BlueSky and R Commander can handle nearly all of these tasks. Others, such as jamovi and RKWard handle only a few of these functions.
JASP’s data management capabilities are minimal. It has a simple calculator that works by dragging and dropping variable names and math or statistical operators. Alternatively, you can type formulas using R code. Using this approach, you can only modify one variable at time, making day-to-day analysis quite tedious. It’s also unable to apply functions across rows (jamovi handles this via a set of row-specific functions). Using the calculator, I could never figure out how to later edit the formula or even delete a variable if I made an error. I tried to recreate one, but it told me the name was already in use.
You can filter cases to work on a subset of your data. However, JASP can’t sort, stack, merge, aggregate, transpose, or reshape datasets. The lack of combining datasets may be a result of the fact that JASP can only have one dataset open in a given session.
Menus & Dialog Boxes
The goal of pointing and clicking your way through an analysis is to save time by recognizing menu settings rather than performing the more difficult task of recalling programming commands. Some GUIs, such as BlueSky and jamovi, make this easy by sticking to menu standards and using simpler dialog boxes; others, such as RKWard, use non-standard menus that are unique to it and hence require more learning.
JASP’s interface uses tabbed windows and toolbars in a way that’s similar to Microsoft Office. As you can see in Figure 3, the “File” tab contains what is essentially a menu, but it’s already in the dropped-down position so there’s no need to click on it. Depending on your selections there, a side menu may pop out, and it stays out without holding the mouse button down.
Figure 3. The File tab which shows menu and sub-menu, which are always “dropped down”.
The built-in set of analytic methods are contained under the “Common” tab. Choosing that yields a shift from menus to toolbar icons shown in Figure 4.
Figure 4. Analysis icons shown on the Common tab.
Clicking on any icon on the toolbar causes a standard dialog box to pop out the right side of the data viewer (Figure 2, center). You select variables to place into their various roles. This is accomplished by either dragging the variable names or by selecting them and clicking an arrow located next to the particular role box. As soon as you fill in enough options to perform an analysis, its output appears instantly in the output window to the right. Thereafter, every option chosen adds to the output immediately; every option turned off removes output. The dialog box does have an “OK” button, but rather than cause the analysis to run, it merely hides the dialog box, making room for more space for the data viewer and output. Clicking on the output itself causes the associated dialog to reappear, allowing you to make changes.
While nearly all GUIs keep your dialog box settings during your session, JASP keeps those settings in its main file. This allows you to return to a given analysis at a future date and try some model variations. You only need to click on the output of any analysis to have the dialog box appear to the right of it, complete with all settings intact.
Output is saved by using the standard “File> Save” selection.
Documentation & Training
The JASP Materials web page provides links to a helpful array of information to get you started. The How to Use JASP web page offers a cornucopia of training materials, including blogs, GIFs, and videos. The free book, Statistical Analysis in JASP: A Guide for Students, covers the basics of using the software and includes a basic introduction to statistical analysis.
Help
R GUIs provide simple task-by-task dialog boxes which generate much more complex code. So for a particular task, you might want to get help on 1) the dialog box’s settings, 2) the custom functions it uses (if any), and 3) the R functions that the custom functions use. Nearly all R GUIs provide all three levels of help when needed. The notable exception that is the R Commander, which lacks help on the dialog boxes themselves.
JASP’s help files are activated by choosing “Help” from the hamburger menu in the upper right corner of the screen (Figure 5). When checked, a window opens on the right of the output window, and its contents change as you scroll through the output. Given that everything appears in a single window, having a large screen is best.
The help files are very well done, explaining what each choice means, its assumptions, and even journal citations. While there is no reference to the R functions used, nor any link to their help files, the overall set of R packages JASP uses is listed here.
Figure 5. JASP with help file open on the left. Click to see a bigger image.
Graphics
The various GUIs available for R handle graphics in several ways. Some, such as RKWard, focus on R’s built-in graphics. Others, such as BlueSky, focus on R’s popular ggplot graphics. GUIs also differ quite a lot in how they control the style of the graphs they generate. Ideally, you could set the style once, and then all graphs would follow it.
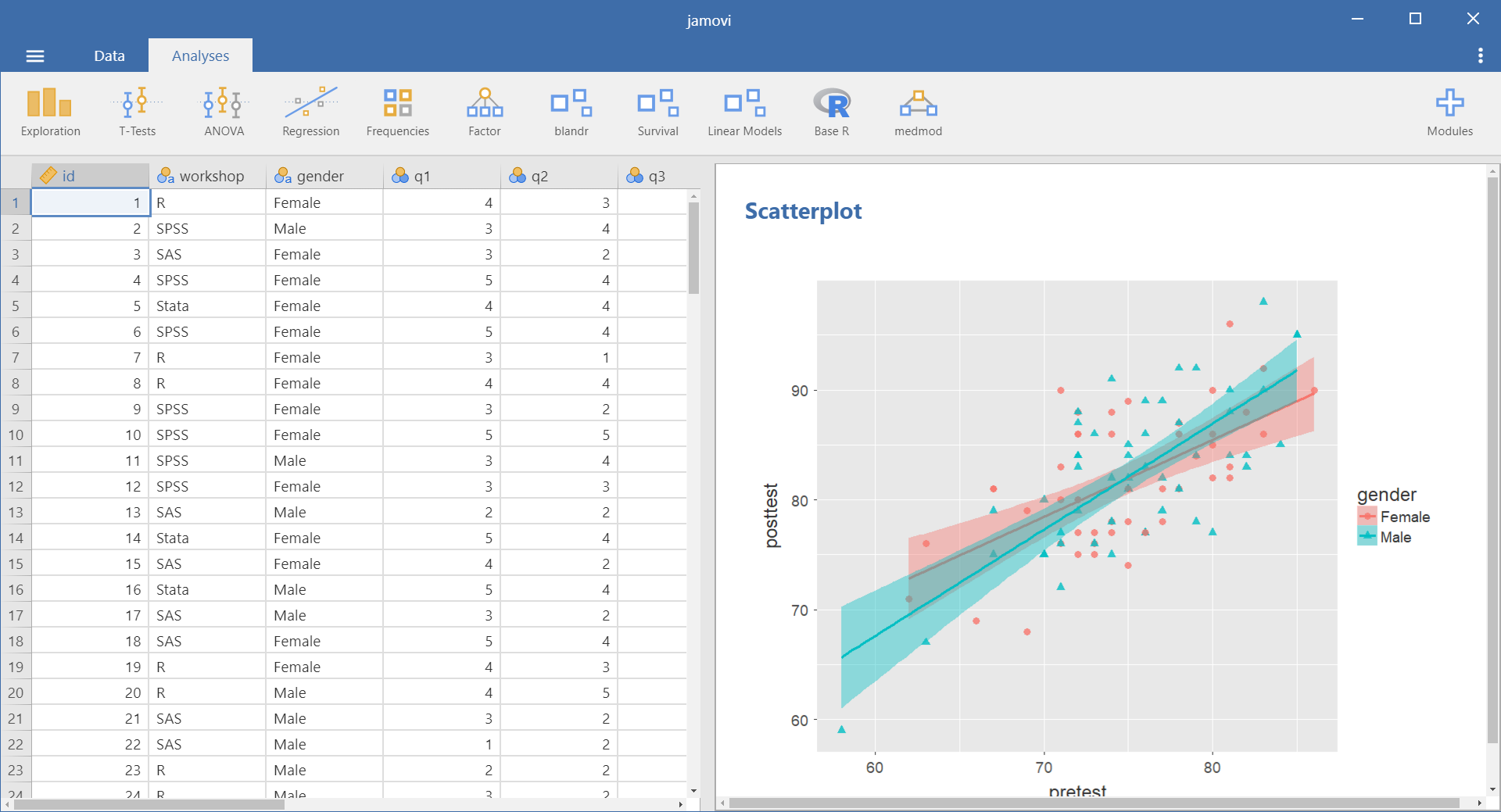
There is no “Graphics” menu in JASP; all the plots are created from within the data analysis dialogs. For example, boxplots are found in “Common> Descriptives> Plots.” To get a scatterplot I tried “Common> Regression> Plots” but only residual plots are found there. Next I tried “Common> Descriptives> Plots> Correlation plots” and was able to create the image shown in Figure 6. Apparently, there is no way to get just a single scatterplot.
The plots JASP creates are well done, with a white background and axes that don’t touch at the corners. It’s not clear which R functions are used to create them as their style is not the default from the R’s default graphics package, ggplot2, or lattice.
Figure 6. The popular scatterplot is only available as part of a scatterplot matrix.
The most important graphical ability that JASP lacks is the ability to do “small multiples” or “facets”. Faceted plots allow you to compare groups by showing a set of the same type of plot repeated by levels of a categorical variable.
Setting the dots-per-inch is the only graphics adjustment JASP offers. It doesn’t support styles or templates. However, plot editing is planned for a future release.
Here is the selection of plots JASP can create.
Histogram
Density
Box Plots
Violin Plots
Strip Plots
Bar Plots
Scatterplot matrix
Scatter – of residuals
Confidence intervals
Modeling
The way statistical models (which R stores in “model objects”) are created and used, is an area on which R GUIs differ the most. The simplest and least flexible approach is taken by RKWard. It tries to do everything you might need in a single dialog box. To an R programmer, that sounds extreme, since R does a lot with model objects. However, neither SAS nor SPSS were able to save models for their first 35 years of existence, so each approach has its merits.
Other GUIs, such as BlueSky and R Commander save R model objects, allowing you to use them for scoring tasks, testing the difference between two models, etc. JASP saves a complete set of analyses, including the steps used to create models. It offers a “Sync Data” option on its File menu that allows you to re-use the entire analysis on a new dataset. However, it does not let you save R model objects.
Analysis Methods
All of the R GUIs offer a decent set of statistical analysis methods. Some also offer machine learning methods. As you can see from the table below, JASP offers the basics of statistical analysis. Included in many of these are Bayesian measures, such as credible intervals. See Plug-in Modules section above for more analysis types.
Analysis
Frequentist
Bayesian
1. ANOVA
✓
✓
2. ANCOVA
✓
✓
3. Binomial Test
✓
✓
4. Contingency Tables (incl. Chi-Squared Test)
✓
✓
5. Correlation: Pearson, Spearman, Kendall
✓
✓
6. Exploratory Factor Analysis (EFA)
✓
–
7. Linear Regression
✓
✓
8. Logistic Regression
✓
–
9. Log-Linear Regression
✓
✓
10. Multinomial
✓
–
11. Principal Component Analysis (PCA)
✓
–
12. Repeated Measures ANOVA
✓
✓
13. Reliability Analyses: α, λ6, and ω
✓
–
14. Structural Equation Modeling (SEM)
✓
–
15. Summary Stats
–
✓
16. T-Tests: Independent, Paired, One-Sample
✓
✓
Generated R Code
One of the aspects that most differentiates the various GUIs for R is the code they generate. If you decide you want to save code, what type of code is best for you? The base R code as provided by the R Commander which can teach you “classic” R? The tidyverse code generated by BlueSky Statistics? The completely transparent (and complex) traditional code provided by RKWard, which might be the best for budding R power users?
JASP uses R code behind the scenes, but currently, it does not show it to you. There is no way to extract that code to run in R by itself. The JASP developers have that on their to-do list.
Support for Programmers
Some of the GUIs reviewed in this series of articles include extensive support for programmers. For example, RKWard offers much of the power of Integrated Development Environments (IDEs) such as RStudio or Eclipse StatET. Others, such as jamovi or the R Commander, offer just a text editor with some syntax checking and code completion suggestions.
JASP’s mission is to make statistical analysis easy through the use of menus and dialog boxes. It installs R and uses it internally, but it doesn’t allow you to access that copy (other than in its data calculator.) If you wish to code in R, you need to install a second copy.
Reproducibility & Sharing
One of the biggest challenges that GUI users face is being able to reproduce their work. Reproducibility is useful for re-running everything on the same dataset if you find a data entry error. It’s also useful for applying your work to new datasets so long as they use the same variable names (or the software can handle name changes). Some scientific journals ask researchers to submit their files (usually code and data) along with their written report so that others can check their work.
As important a topic as it is, reproducibility is a problem for GUI users, a problem that has only recently been solved by some software developers. Most GUIs (e.g. the R Commander, Rattle) save only code, but since GUI users don’t write the code, they also can’t read it or change it! Others such as jamovi, RKWard, and the newest version of SPSS, save the dialog box entries and allow GUI users to have reproducibility in the form they prefer.
JASP records the steps of all analyses, providing exact reproducibility. In addition, if you update a data value, all the analyses that used that variable are recalculated instantly. That’s a very useful feature since people coming from Excel expect this to happen. You can also use “File> Sync Data” to open a new data file and rerun all analyses on that new dataset. However, the dataset must have exactly the same variable names in the same order for this to work. Still, it’s a very feature that GUI users will find very useful. If you wish to share your work with a colleague so they too can execute it, they must be JASP users. There is no way to export an R program file for them to use. You need to send them only your JASP file; It contains both the data and the steps you used to analyze it.
Package Management
A topic related to reproducibility is package management. One of the major advantages to the R language is that it’s very easy to extend its capabilities through add-on packages. However, updates in these packages may break a previously functioning analysis. Years from now you may need to run a variation of an analysis, which would require you to find the version of R you used, plus the packages you used at the time. As a GUI user, you’d also need to find the version of the GUI that was compatible with that version of R.
Some GUIs, such as the R Commander and Deducer, depend on you to find and install R. For them, the problem is left for you to solve. Others, such as BlueSky, distribute their own version of R, all R packages, and all of its add-on modules. This requires a bigger installation file, but it makes dealing with long-term stability as simple as finding the version you used when you last performed a particular analysis. Of course, this depends on all major versions being around for long-term, but for open-source software, there are usually multiple archives available to store software even if the original project is defunct.
JASP if firmly in the latter camp. It provides nearly everything you need in a single download. This includes the JASP interface, R itself, and all R packages that it uses. So for the base package, you’re all set.
Output & Report Writing
Ideally, output should be clearly labeled, well organized, and of publication quality. It might also delve into the realm of word processing through R Markdown, knitr or Sweave documents. At the moment, none of the GUIs covered in this series of reviews meets all of these requirements. See the separate reviews to see how each of the other packages is doing on this topic.
The labels for each of JASP’s analyses are provided by a single main title which is editable, and subtitles, which are not. Pointing at a title will cause a black triangle to appear, and clicking that will drop a menu down to edit the title (the single main one only) or to add a comment below (possible with all titles).
The organization of the output is in time-order only. You can remove an analysis, but you cannot move it into an order that may make more sense after you see it.
While tables of contents are commonly used in GUIs to let you jump directly to a section, or to re-order, rename, or delete bits of output, that feature is not available in JASP.
Those limitations aside, JASP’s output quality is very high, with nice fonts and true rich text tables (Figure 7). Tabular output is displayed in the popular style of the American Psychological Association. That means you can right-click on any table and choose “Copy” and the formatting is retained. That really helps speed your work as R output defaults to mono-spaced fonts that require additional steps to get into publication form (e.g. using functions from packages such as xtable or texreg). You can also export an entire set of analyses to HTML, then open the nicely-formatted tables in Word.
Figure 7. Output as it appers after pasting into Word. All formatting came directly from JASP.
LaTeX users can right-click on any output table and choose “Copy special> LaTeX code” to to recreate the table in that text formatting language.
Group-By Analyses
Repeating an analysis on different groups of observations is a core task in data science. Software needs to provide an ability to select a subset one group to analyze, then another subset to compare it to. All the R GUIs reviewed in this series can do this task. JASP allows you to select the observation to analyze in two ways. First, clicking the funnel icon located at the upper left corner of the data viewer opens a window that allows you to enter your selection logic, such as “gender = Female”. From an R code perspective, it does not use R’s “==” symbol for logical equivalence, nor does it allow you to put value labels in quotes. It generates a subset that you can analyze in the same way as the entire dataset. Second, you can click on the name of a factor, then check or un-check the values you wish to keep. Either way, the data viewer grays out the excluded data lines to give you a visual cue.
Software also needs the ability to automate such selections so that you might generate dozens of analyses, one group at a time. While this has been available in commercial GUIs for decades (e.g. SPSS “split-file”, SAS “by” statement), BlueSky is the only R GUI reviewed here that includes this feature. The closest JASP gets on this topic is to offer a “split” variable selection box in its Descriptives procedure.
Output Management
Early in the development of statistical software, developers tried to guess what output would be important to save to a new dataset (e.g. predicted values, factor scores), and the ability to save such output was built into the analysis procedures themselves. However, researchers were far more creative than the developers anticipated. To better meet their needs, output management systems were created and tacked on to existing tools (e.g. SAS’ Output Delivery System, SPSS’ Output Management System). One of R’s greatest strengths is that every bit of output can be readily used as input. However, for the simplification that GUIs provide, that’s a challenge.
Output data can be observation-level, such as predicted values for each observation or case. When group-by analyses are run, the output data can also be observation-level, but now the (e.g.) predicted values would be created by individual models for each group, rather than one model based on the entire original data set (perhaps with group included as a set of indicator variables).
You can also use group-by analyses to create model-level data sets, such as one R-squared value for each group’s model. You can also create parameter-level data sets, such as the p-value for each regression parameter for each group’s model. (Saving and using single models is covered under “Modeling” above.)
For example, in our organization, we have 250 departments and want to see if any of them have a gender bias on salary. We write all 250 regression models to a dataset, and then search to find those whose gender parameter is significant (hoping to find none, of course!)
BlueSky is the only R GUI reviewed here that does all three levels of output management. JASP not only lacks these three levels of output management, it even lacks the fundamental observation-level saving that SAS and SPSS offered in their first versions back in the early 1970s. This entails saving predicted values or residuals from regression, or scores from principal components analysis or factor analysis. The developers plan to add that capability to a future release.
Developer Issues
While most of the R GUI projects encourage module development by volunteers, the JASP project hasn’t done so. However, this is planned for a future release.
Conclusion
JASP is easy to learn and use. The tables and graphs it produces follow the guidelines of the Americal Psychological Association, making them acceptable by many scientific journals without any additional formatting. Its developers have chosen their options carefully so that each analysis includes what a researcher would want to see. Its coverage of Bayesian methods is the most extensive I’ve seen in this series of software reviews.
As nice as JASP is, it lacks important features, including: a data editor, an R code editor, the ability to see the R code it writes, the ability to handle date/time variables, the ability to read/write R, SAS, and Stata data files, the ability to perform many more fundamental data management tasks, the ability to save new variables such as predicted values or factor scores, the ability to save models so they can be tested on hold-out samples or new data sets, and the ability to reuse an analysis on new data sets using the GUI. While those are quite a few features to add, JASP is funded by several large grants from the Dutch Science Foundation and the ERC, allowing them to guarantee continuous and ongoing development.
Acknowledgements
Thanks to Eric-Jan Wagenmakers and Bruno Boutin for their help in understanding JASP’s finer points. Thanks also to Rachel Ladd, Ruben Ortiz, Christina Peterson, and Josh Price for their editorial suggestions. Edit
Last February I reviewed the jamovi menu-based front end to R. I’ve reviewed five more user interfaces since then, and have developed a more comprehensive template to make it easier to compare them all. Now I’m cycling back to jamovi, using that template to write a far more comprehensive review. I’ve added this review to the previous set, and I’m releasing it as a blog post so that it will be syndicated on R-Bloggers, StatsBlogs, et al.
Introduction
jamovi (spelled with a lower-case “j”) is a free and open source graphical user interface for the R software that targets beginners looking to point-and-click their way through analyses. It is available for Windows, Mac, Linux, and even ChromeOS. Versions are also planned for servers and tablets.
This post is one of a series of reviews which aim to help non-programmers choose the Graphical User Interface (GUI) for R that is best for them. Additionally, these reviews include cursory descriptions of the programming support that each GUI offers.
Figure 1. jamovi’s main screen.
Terminology
There are various definitions of user interface types, so here’s how I’ll be using these terms:
GUI = Graphical User Interface using menus and dialog boxes to avoid having to type programming code. I do not include any assistance for programming in this definition. So, GUI users are people who prefer using a GUI to perform their analyses. They don’t have the time or inclination to become good programmers.
IDE = Integrated Development Environment which helps programmers write code. I do not include point-and-click style menus and dialog boxes when using this term. IDE users are people who prefer to write R code to perform their analyses.
Installation
The various user interfaces available for R differ quite a lot in how they’re installed. Some, such as BlueSky Statistics or RKWard, install in a single step. Others install in multiple steps, such as R Commander (two steps), and Deducer (up to seven steps). Advanced computer users often don’t appreciate how lost beginners can become while attempting even a simple installation. The HelpDesks at most universities are flooded with such calls at the beginning of each semester!
jamovi’s single-step installation is extremely easy and includes its own copy of R. So if you already have a copy of R installed, you’ll have two after installing jamovi. That’s a good idea though, as it guarantees compatibility with the version of R that it uses, plus a standard R installation by itself is harder than jamovi’s. Python is also installed with jamovi, but it is used only for internal purposes. You can directly control only R through jamovi.
Plug-in Modules
When choosing a GUI, one of the most fundamental questions is: what can it do for you? What the initial software installation of each GUI gets you is covered in the Graphics, Analysis, and Modeling sections of this series of articles. Regardless of what comes built-in, it’s good to know how active the development community is. They contribute “plug-ins” which add new menus and dialog boxes to the GUI. This level of activity ranges from very low (RKWard, Deducer) to very high (R Commander).
For jamovi, plug-ins are called “modules” and they are found in the “jamovi library” rather than on the Comprehensive R Archive Network (CRAN) where R and most of its packages are found. This makes locating and installing jamovi modules especially easy.
Although jamovi is one of the most recent GUIs to appear on the R scene, it has already attracted a respectable number of developers. The list of modules at publication time is listed below. You can check on the latest ones on this web page.
Base R – converts jamovi analyses into standard R functions
blandr – Bland-Altman method comparison analysis, and is also available as an R package from CRAN
Death Watch – survival analysis
Distraction – quantiles and probabilities of continuous and discrete distributions
GAMLj – general linear model, linear mixed model, generalized linear models, etc.
jpower – power analysis for common research designs
MAJOR – meta-analysis based on R’s metafor package
medmod – basic mediation and moderation analysis
jAMM – advanced mediation analysis (similar to the popular Process Macro for SAS and SPSS)
R Data Sets
RJ – editor to run R code inside jamovi
scatr – scatter plots with marginal density or box plots
Statkat – helps you choose a statistical test.
TOSTER – tests of equivalence for t-tests and correlation
Walrus – robust descriptive stats & tests
jamovi Arcade – hangman & blackjack games
Startup
Some user interfaces for R, such as BlueSky and Rkward, start by double-clicking on a single icon, which is great for people who prefer to not write code. Others, such as R commander and JGR, have you start R, then load a package from your library, and then call a function to finally activate the GUI. That’s more appropriate for people looking to learn R, as those are among the first tasks they’ll have to learn anyway.
You start jamovi directly by double-clicking its icon from your desktop, or choosing it from your Start Menu (i.e. not from within R itself). It interacts with R in the background; you never need to be aware that R is running.
Data Editor
A data editor is a fundamental feature in data analysis software. It puts you in touch with your data and lets you get a feel for it, if only in a rough way. A data editor is such a simple concept that you might think there would be hardly any differences in how they work in different GUIs. While there are technical differences, to a beginner what matters the most are the differences in simplicity. Some GUIs, including BlueSky, let you create only what R calls a data frame. They use more common terminology and call it a data set: you create one, you save one, later you open one, then you use one. Others, such as RKWard trade this simplicity for the full R language perspective: a data set is stored in a workspace. So the process goes: you create a data set, you save a workspace, you open a workspace, and choose a dataset from within it.
jamovi’s data editor appears at start-up (Figure 1, left) and prompts you to enter data with an empty spreadsheet-style data editor. You can start entering data immediately, though at first, the variables are simply named A, B, C….
To change metadata, such as variable names, you double click on a name, and window (Figure 2) will slide open from the top with settings for variable name, description, measurement level (continuous, ordinal, nominal, or ID), data type (integer, decimal, text), variable levels (labels) and a “retain unused levels” switch. Currently, jamovi has no date format, which is a serious limitation if you deal with that popular data format.
Figure 2. The jamovi data editor with the variable attributes window open, allowing you to make changes.
When choosing variable terminology, R GUI designers have two choices: follow what most statistics books use, or instead use R jargon. The jamovi designers have opted for the statistics book terminology. For example, what jamovi calls categorical, decimal, or text are called factor, numeric, or character in R. Both sets of terms are fairly easy to learn, but given that some jamovi users may wish to learn R code, I find that choice puzzling. Changing variable settings can be done to many variables at once, which is an important time saver.
You can enter integer, decimal, or character data in the editor right after starting jamovi. It will recognize those types and set their metadata accordingly.
To enter nominal/factor data, you are free to enter numbers, such as 1/2 and later set levels to see Male/Female appear. Or you can set it up in advance and enter the numbers which will instantly turn into labels. That is a feature that saves time and helps assure accuracy. All data editors should offer that choice!
Adding variables or observations is as simple as scrolling beyond the set’s current limits and entering additional data. jamovi does not require “add more” buttons as some of its competitors (e.g. BlueSky) do. Adding variables or observations in between existing ones is also easy. Under the “Data” tab, there are two sets of “Add” and “Delete” buttons. The first set deals with variables and the second with cases. You can use the first set to insert, compute, transform variables or delete variables. The second inserts, appends, or deletes cases. These two sets of buttons are labeled “Variables” and “Rows”, but the font used is so small that I used jamovi for quite a while before noticing these labels.
Data Import
The ability to import data from a wide variety of formats is extremely important; you can’t analyze what you can’t access. Most of the GUIs evaluated in this series can open a wide range of file types and even pull data from relational databases. jamovi can’t read data from databases, but it can import the following file formats:
Comma Separated Values (.csv)
Plain text files (.txt)
SPSS (.sav, .zsav, .por)
SAS binary files (.sas7bdat, .xpt)
JASP (.jasp)
While jamovi doesn’t support true date/time variables, when you import a dataset that contains them, it will convert them to an integer value representing the number of days since 1970-01-01 and assign them labels in the YYYY-MM-DD format.
Data Export
The ability to export data to a wide range of file types helps when you have to use multiple tools to complete a task. Research is commonly a team effort, and in my experience, it’s rare to have all team members prefer to use the same tool. For these reasons, GUIs such as BlueSky and Deducer offer many export formats. Others, such as R Commander and RKward can create only delimited text files.
A fairly unique feature of jamovi is that it doesn’t save just a dataset, but instead it saves the combination of a dataset plus its associated analyses. To save just the dataset, you use the menu (a.k.a. hamburger) menu to select “Export” then “Data.” The export formats supported are the same as those provided for import, except for the more rarely-used ones such as SAS xpt and SPSS por and zsav:
Comma Separated Values (.csv)
Plain text files (.txt)
SPSS (.sav)
SAS binary files (.sas7bdat)
Data Management
It’s often said that 80% of data analysis time is spent preparing the data. Variables need to be transformed, recoded, or created; strings and dates need to be manipulated; missing values need to be handled; datasets need to be sorted, stacked, merged, aggregated, transposed, or reshaped (e.g. from “wide” format to “long” and back).
A critically important aspect of data management is the ability to transform many variables at once. For example, social scientists need to recode many survey items, biologists need to take the logarithms of many variables. Doing these types of tasks one variable at a time is tedious.
Some GUIs, such as BlueSky and R Commander can handle nearly all of these tasks. Others, such as RKWard handle only a few of these functions.
jamovi’s data management capabilities are minimal. You can transform or recode variables, and doing so across many variables is easy. The transformations are stored in the variable itself, making it easy to see what it was by double-clicking its name. However, the R code for the transformation is not available, even in with Syntax Mode turned on.
You can also filter cases to work on a subset of your data. However, jamovi can’t sort, stack, merge, aggregate, transpose, or reshape datasets. The lack of combining datasets may be a result of the fact that jamovi can only have one dataset open in a given session.
Menus & Dialog Boxes
The goal of pointing and clicking your way through an analysis is to save time by recognizing menu settings rather than performing the more difficult task of recalling programming commands. Some GUIs, such as BlueSky, make this easy by sticking to menu standards and using simpler dialog boxes; others, such as RKWard, use non-standard menus that are unique to it and hence require more learning.
jamovi uses standard menu choices for running steps listed on the Data and Analyses tabs. Dialog boxes appear and you select variables to place into their various roles. This is accomplished by either dragging the variable names or by selecting them and clicking an arrow located next to the particular role box. A unique feature of jamovi is that as soon as you fill in enough options to perform an analysis, its output appears instantly. There is no “OK” or “Run” button as the other GUIs reviewed here have. Thereafter, every option chosen adds to the output immediately; every option turned off is removed.
While nearly all GUIs keep your dialog box settings during your session, jamovi keeps those settings in its main “workspace” file. This allows you to return to a given analysis at a future date and try some model variations. You only need to click on the output of any analysis to have the dialog box appear to the right of it, complete with all settings intact.
Under the triple-dot menu on the upper right side of the screen, you can choose to run “Syntax Mode.” When you turn that on, the R syntax appears immediately, and when you turn it off, it vanishes just as quickly. Turning on syntax mode is the only way a jamovi user would be aware that R is doing the work in the background.
Output is saved by using the standard “Menu> Save” selection.
Documentation & Training
The jamovi User Guide covers the basics of using the software. The Resources by the Community web page provides links to a helpful array of documentation and tutorials in written and video form.
Help
R GUIs provide simple task-by-task dialog boxes which generate much more complex code. So for a particular task, you might want to get help on 1) the dialog box’s settings, 2) the custom functions it uses (if any), and 3) the R functions that the custom functions use. Nearly all R GUIs provide all three levels of help when needed. The notable exception that is the R Commander, which lacks help on the dialog boxes themselves.
jamovi doesn’t offer any integrated help files, only the documentation described in the Documentation & Training section above. The search for help can become very confusing. For example, after doing the scatterplot shown in the next section, I wondered if the scat() function offered a facet argument, normally this would be an easy question to answer. My initial attempt was to go to RStudio, load jamovi’s jmv package knowing that I routinely get help from it. However, the scat() function is not built into jamovi (or jmv); it comes in the scatr add-on module. So I had to return to jamovi and install Rj Editor module. That module lets you execute R code from within jamovi. However, running “help(scat)” yielded no result. After so much confusion, I never was able to find any help on that function. Hopefully, this situation will improve as jamovi matures.
Graphics
The various GUIs available for R handle graphics in several ways. Some, such as RKWard, focus on R’s built-in graphics. Others, such as BlueSky, focus on R’s popular ggplot graphics. GUIs also differ quite a lot in how they control the style of the graphs they generate. Ideally, you could set the style once, and then all graphs would follow it.
jamovi uses its own graphics functions to create plots. By default, they have the look of the popular ggplot2 package. jamovi is the only R GUI reviewed that lets you set the plot style in advance, and all future plots will use that style. It does this using four popular themes. jamovi also lets you choose color palettes in advance, from a set of eight.
It has been just a few months since I reviewed five free and open-source point-and-click graphical user interfaces (GUIs) to the R language. I plan to keep those reviews up to date as new features are added. BlueSky’s interface would be immediately familiar to anyone who had used SPSS, as its developers model it on that popular software. The BlueSky developers’ goal is to help people use R without having to learn to write computer code.
While the previous version of BlueSky offered dozens of fairly advanced modeling methods such as generalized linear models, random forests, and support vector machines, it lacked some simpler features. Version 5.40 (correction: this was previously listed as version 6.04) adds a dialog for logistic regression, which is essentially its glm dialog simplified to do only logistic regression.
The Multi-Way ANOVA output has also been greatly enhanced, with the addition of a wide range of contrasts from the emmeans package, support for all three types of sums of squares, and plots for both post-hoc main-effects comparisons and interaction plots like this one:
Users of RStudio will be pleased that the BlueSky’s program editor now submits lines of code like RStudio does so you can step your way through a program line-by-line, by clicking the Run button repeatedly.
The new version also has functions to do string-to-date vice versa, which led me to realize I had totally missed the string and date functions that it already had. In the “Data> Compute” dialog, the functions for Arithmetic, Logical, Math, and String(1) are visible. But if you click on the “>>” arrow on the right, you’ll also see String (2), Conversion, Statistical, Random Numbers, and four different menus of Date functions.
The complete set of new features and bug fixes is below. You can read my full review of BlueSky here, and you download the software for free here. I plan to write about new features in other R GUIs, so stay tuned to my blog or follow me on twitter where I announce new posts. Happy computing!
NEW FEATURES:
=============
1) Added support for weighted datasets. This option is available in Data -> Set Weights. Once you specify the weighting variable we create a new dataset with rows replicated as defined in the weights. This is similar to what SPSS does internally. When you run frequencies, independent sample t-tests, graphics commands, statistical tests etc on the new dataset (in BlueSky Statistics) with the rows replicated you will see results identical to those in SPSS.
2) Added the option to specify a weighting variable in Linear and Logistic Regression. This allows an optional vector of weights to be used during the fitting process (i.e. the weighted least-squares solution).
3) Added support for logistic regression under ‘Model Fitting’. Once the model is built, you can score the dataset, optionally obtain a confusion matrix, model statistics, and a ROC curve by selecting the model and clicking score. This is available on the top right-hand corner of the main application window.
4) We have updated the “Multi Way Anova” dialog with following capabilities:
display contrasts.
interaction plots.
support for type I, type II and type III tests.
pairwise comparison.
5) New reshape dialog with simplified R syntax has been added, using the tidyr package.
6) The “Multi variable one sample T-Test” and “Multi variable independent sample T-Test(with factor)” have been updated to allow you to specify the alternative hypothesis.
7) Added capabilities to support date manipulations.
The “String to date” dialog allows you to convert string to POSIXct date class.
The “Date to string” dialog allows you to convert the date (POSIXct and Date class) to string.
8) Simplified the syntax for frequencies and factor analysis.
9) If you launch a second instance of BlueSky Statistics the message that gets displayed has been improved. NOTE: You can only have one BlueSky Statistics instance running at a time.
10) We have improved the ability to browse the contents of the output window in BlueSky Statistics. This can be accessed from the menu (Layout > Show Navigation Tree).
11) Items in the output window can now be deleted. To delete an item from the output, just right click on the item(table/text/graphics) and choose the “Delete” option.
12) To make the output visually more appealing, we have introduced an option to hide the R syntax that gets displayed in the output window. This is controlled by an option in the configuration window ( Tools > Configuration Settings > Output tab ). By default we hide the R syntax in the output window.
13) When the option to show R syntax in the output is turned on ( Tools > Configuration Settings > Output tab ) and you resize the output window, we wrap the R syntax so that it is always visible.
14) To run any line of R syntax just place the cursor on that line and hit the RUN button, you don’t have to select the entire line.
15) If you want to run your R script line by line, place your cursor on the first line and hit RUN, the cursor will automatically move to the next line and you can hit the RUN button again.
This feature will work for simple R syntax which does not span multiple lines.
Example 1: 3 lines below work
a=10
b=20
c=a+b
Example 2: 4 lines below will not work
if(TRUE)
{
print(“Great”)
}
16)Added helpful hints to indicate you have reached the beginning and end of a dataset when scrolling wide datasets. This is available on the paging controls on the bottom right-hand corner of the screen.
17) Application launch is now faster.
18) In the BlueSky Statistics syntax editor, just like a comma, the pipe (%>%) can be used to break a long R code statement.
19) When the application launches, we open a new blank dataset this has been populated with zeros. You can right click on a row to delete a row or go into ‘Data -> Delete Variables’ to delete variables.
20) Clicking on a variable name in the data grid sorts in ascending order by that variable name. Clicking again sorts in descending order.
BUG FIXES:
=============
1) Fixed an issue with factor analysis when saving scores using the regression method.
2) Fixed an issue when re-editing factor levels that were previously changed in the variable grid. This would result in the dialog not functioning correctly and incorrect levels being added.
3) Fixed an issue when you closed the empty dataset that gets created when BlueSky Statistics is launched and then attempted to save open datasets- those datasets would not get saved correctly.
4) Fixed an issue that was limiting the number of variables that Factor Analysis can be run across.
5) Within block commands that use ‘local()’, cat(“\n”) can now be printed in the output to leave some extra spaces.
6) When you added a new factor variable and renamed the variable using the user interface and then tried to add new levels – this did not work and has been fixed.
7) Add new factor variable. Click in the cell where the new variable name is shown. Cell goes in edit mode. Now add new factor levels to this new variable. Switch to the data grid and select a different level. Switch back to ‘Variables’ tab and the application crashes. This has been fixed.
8) When any existing factor level name is modified using the user interface, a blank level automatically gets added. If you try to modify the level, it does not take effect. This has been addressed.
9) Disable data grid navigation buttons (on the lower right-hand side of the data grid) if there are less than 16 columns in the dataset.
10) Changing factor levels was not working because one or more levels had a single quote in the level name.
11) Aggregate control fixed: Text above the drop-down (that contains mean, median etc.) was getting chopped off. Similar issue with the label text above a textbox (which was almost at the bottom of the dialog).
12) Fixed significance codes for:
One Sample T Test and Independent Sample T Test
Multivariable one sample t-test and Multivariable Independent one sample t-test (with factor)
13) Fixed a defect: Select some syntax and hit RUN. After execution, the cursor goes to the top of the script. Now it moves to the next line.
14) Data grid navigation buttons are disabled if either end of the datagrid is reached. If there are no more columns on the right, the right navigation button is disabled. If there are no more columns on the left then left navigation button is disabled.
15) Left navigation tree in the output window is fixed for look and feel. It now has a cleaner look. To access left navigation, go to Layout -> Show navigation tree
16) In the R syntax editor, we now ignore square, curly and round brackets that appear inside single or double quotes. See example below: