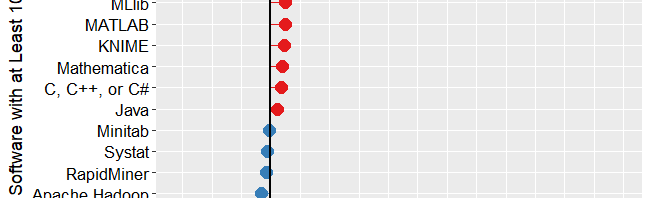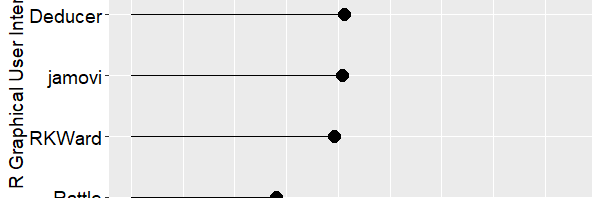
It has been only two months since I summarized my reviews of point-and-click front ends for R, and it’s already out of date! I have converted that post into a regularly-updated article and added a plot of total features, which I repeat below. It shows the total number of features in each package, including the latest versions of BlueSky Statistics, JASP, and jamovi. The reviews which initially appeared as blog posts are now regularly-updated pages.

New Features in JASP
Let’s take a look at some of the new features, starting with the version of JASP that was released three hours ago:
- Interface adjustments
- Data panel, analysis input panel and results panel can be manipulated much more intuitively with sliders and show/hide buttons
- Changed the analysis input panel to have an overview of all opened analyses and added the possibility to change titles, to show documentation, and remove analyses
- Enhanced the navigation through the file menu; it is now possible to use arrow keys or simply hover over the buttons
- Added possibility to scale the entire application with Ctrl +, Ctrl – and Ctrl 0
- Added MANOVA
- Added Confirmatory Factor Analysis
- Added Bayesian Multinomial Test
- Included additional menu preferences to customize JASP to your needs
- Added/updated help files for most analyses
- R engine updated from 3.4.4 to 3.5.2
- Added Šidák correction for post-hoc tests (AN(C)OVA)
A complete list of fixes and features is available here. JASP is available for free from their download page. My comparative review of JASP is here.
New Features in jamovi
Two of the usability features added to jamovi recently are templates and multi-file input. Both are described in detail here.
Templates enable you to save all the steps in your work as a template file. Opening that file in jamovi then lets you open a new dataset and the template will recreate all the previous analyses and graphs using the new data. It provides reusability without having to depend on the R code that GUI users are trying to avoid using.
The multi-file input lets you select many CSV files at once and jamovi will open and stack them all (they must contain common variable names, of course).
Other new analytic features have been added with a set of modeling modules. They’re described in detail here, and a list of some of their capability is below. You can read my full review of jamovi here, and you can download it for free here.
- OLS Regression (GLM)
- OLS ANOVA (GLM)
- OLS ANCOVA (GLM)
- Random coefficients regression (Mixed)
- Random coefficients ANOVA-ANCOVA (Mixed)
- Logistic regression (GZLM)
- Logistic ANOVA-like model (GZLM)
- Probit regression (GZLM)
- Probit ANOVA-like model (GZLM)
- Multinomial regression (GZLM)
- Multinomial ANOVA-like model (GZLM)
- Poisson regression (GZLM)
- Poisson ANOVA-like model (GZLM)
- Overdispersed Poisson regression (GZLM)
- Overdispersed Poisson ANOVA-like model (GZLM)
- Negative binomial regression (GZLM)
- Negative binomial ANOVA-like model (GZLM)
- Continuous and categorical independent variables
- Omnibus tests and parameter estimates
- Confidence intervals
- Simple slopes analysis
- Simple effects
- Post-hoc tests
- Plots for up to three-way interactions for both categorical and continuous independent variables.
- Automatic selection of best estimation methods and degrees of freedom selection
- Type III estimation
New Features in BlueSky Statistics
The BlueSky developers have been working on adding psychometric methods (for a book that is due out soon) and support for distributions. My full review is here and you can download BlueSky Statistics for free here.
- Model Fitting: IRT: Simple Rasch Model
- Model Fitting: IRT: Simple Rasch Model (Multi-Faceted)
- Model Fitting: IRT: Partial Credit Model
- Model Fitting: IRT: Partial Credit Model (Multi-Faceted)
- Model Fitting: IRT: Rating Scale Model
- Model Fitting: IRT: Rating Scale Model (Multi-Faceted)
- Model Statistics: IRT: ICC Plots
- Model Statistics: IRT: Item Fit
- Model Statistics: IRT: Plot PI Map
- Model Statistics: IRT: Item and Test Information
- Model Statistics: IRT: Likelihood Ratio and Beta plots
- Model Statistics: IRT: Personfit
- Distributions: Continuous: BetaProbabilities
- Distributions: Continuous: Beta Quantiles
- Distributions: Continuous: Plot Beta Distribution
- Distributions: Continuous: Sample from Beta Distribution
- Distributions: Continuous: Cauchy Probabilities
- Distributions: Continuous: Plot Cauchy Distribution
- Distributions: Continuous: Cauchy Quantiles
- Distributions: Continuous: Sample from Cauchy Distribution
- Distributions: Continuous: Sample from Cauchy Distribution
- Distributions: Continuous: Chi-squared Probabilities
- Distributions: Continuous: Chi-squared Quantiles
- Distributions: Continuous: Plot Chi-squared Distribution
- Distributions: Continuous: Sample from Chi-squared Distribution
- Distributions: Continuous: Exponential Probabilities
- Distributions: Continuous: Exponential Quantiles
- Distributions: Continuous: Plot Exponential Distribution
- Distributions: Continuous: Sample from Exponential Distribution
- Distributions: Continuous: F Probabilities
- Distributions: Continuous: F Quantiles
- Distributions: Continuous: Plot F Distribution
- Distributions: Continuous: Sample from F Distribution
- Distributions: Continuous: Gamma Probabilities
- Distributions: Continuous: Gamma Quantiles
- Distributions: Continuous: Plot Gamma Distribution
- Distributions: Continuous: Sample from Gamma Distribution
- Distributions: Continuous: Gumbel Probabilities
- Distributions: Continuous: Gumbel Quantiles
- Distributions: Continuous: Plot Gumbel Distribution
- Distributions: Continuous: Sample from Gumbel Distribution
- Distributions: Continuous: Logistic Probabilities
- Distributions: Continuous: Logistic Quantiles
- Distributions: Continuous: Plot Logistic Distribution
- Distributions: Continuous: Sample from Logistic Distribution
- Distributions: Continuous: Lognormal Probabilities
- Distributions: Continuous: Lognormal Quantiles
- Distributions: Continuous: Plot Lognormal Distribution
- Distributions: Continuous: Sample from Lognormal Distribution
- Distributions: Continuous: Normal Probabilities
- Distributions: Continuous: Normal Quantiles
- Distributions: Continuous: Plot Normal Distribution
- Distributions: Continuous: Sample from Normal Distribution
- Distributions: Continuous: t Probabilities
- Distributions: Continuous: t Quantiles
- Distributions: Continuous: Plot t Distribution
- Distributions: Continuous: Sample from t Distribution
- Distributions: Continuous: Uniform Probabilities
- Distributions: Continuous: Uniform Quantiles
- Distributions: Continuous: Plot Uniform Distribution
- Distributions: Continuous: Sample from Uniform Distribution
- Distributions: Continuous: Weibull Probabilities
- Distributions: Continuous: Weibull Quantiles
- Distributions: Continuous: Plot Weibull Distribution
- Distributions: Continuous: Sample from Weibull Distribution
- Distributions: Discrete: Binomial Probabilities
- Distributions: Discrete: Binomial Quantiles
- Distributions: Discrete: Binomial Tail Probabilities
- Distributions: Discrete: Plot Binomial Distribution
- Distributions: Discrete: Sample from Binomial Distribution
- Distributions: Discrete: Geometric Probabilities
- Distributions: Discrete: Geometric Quantiles
- Distributions: Discrete: Geometric Tail Probabilities
- Distributions: Discrete: Plot Geometric Distribution
- Distributions: Discrete: Sample from Geometric Distribution
- Distributions: Discrete: Hypergeometric Probabilities
- Distributions: Discrete: Hypergeometric Quantiles
- Distributions: Discrete: Hypergeometric Tail Probabilities
- Distributions: Discrete: Plot Hypergeometric Distribution
- Distributions: Discrete: Sample from Hypergeometric Distribution
- Distributions: Discrete: Negative Binomial Probabilities
- Distributions: Discrete: Negative Binomial Quantiles
- Distributions: Discrete: Negative Binomial Tail Probabilities
- Distributions: Discrete: Plot Negative Binomial Distribution
- Distributions: Discrete: Sample from Negative Binomial Distribution
- Distributions: Discrete: Poisson Probabilities
- Distributions: Discrete: Poisson Quantiles
- Distributions: Discrete: Poisson Tail Probabilities
- Distributions: Discrete: Plot Poisson Distribution
- Distributions: Discrete: Sample from Poisson Distribution