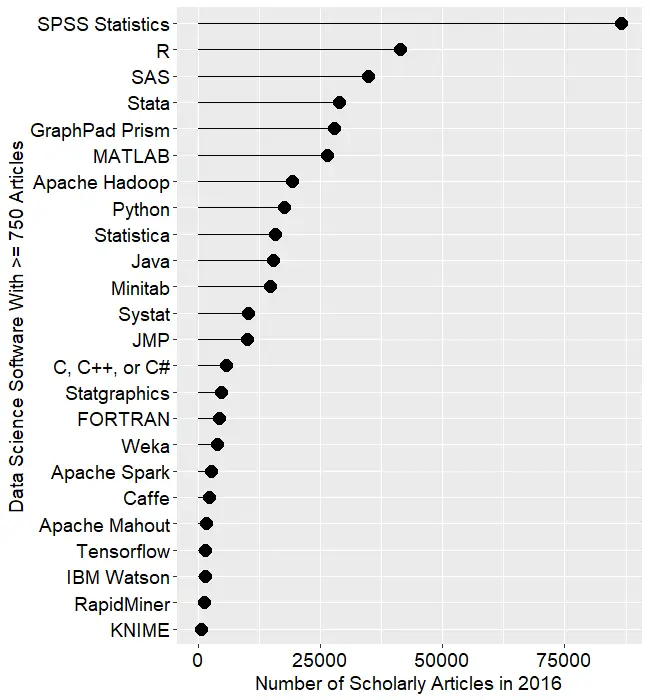
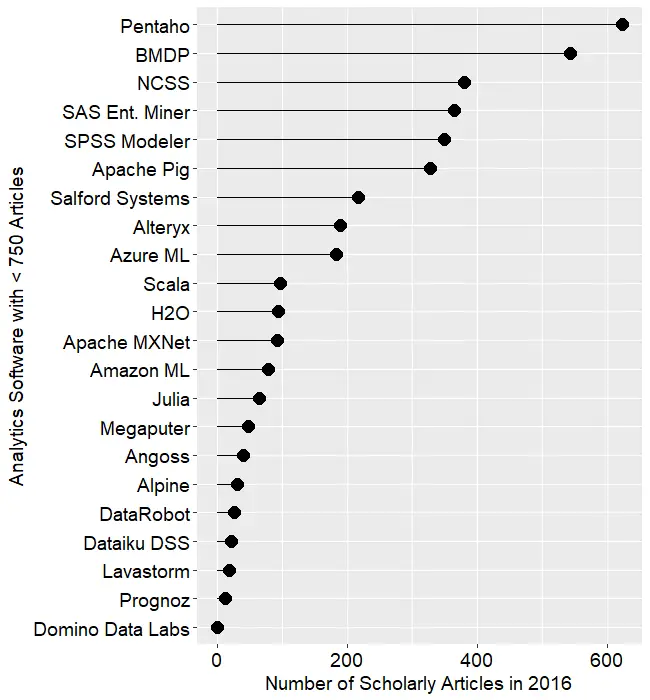
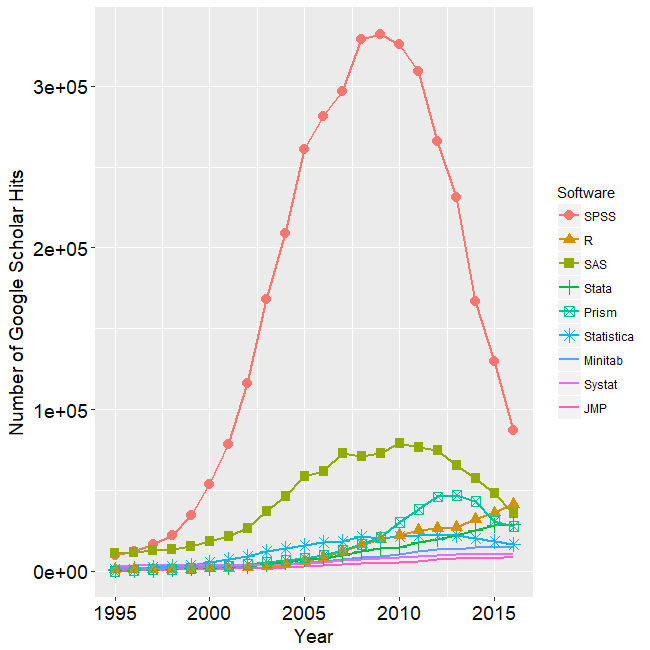
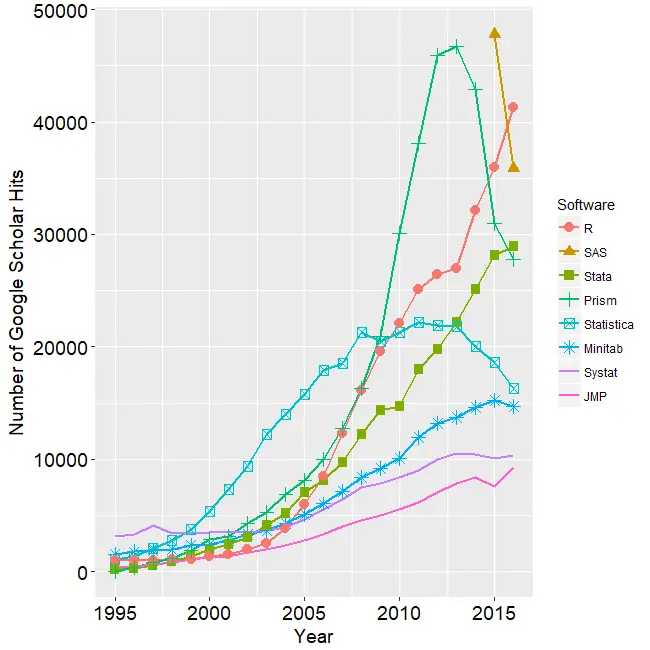
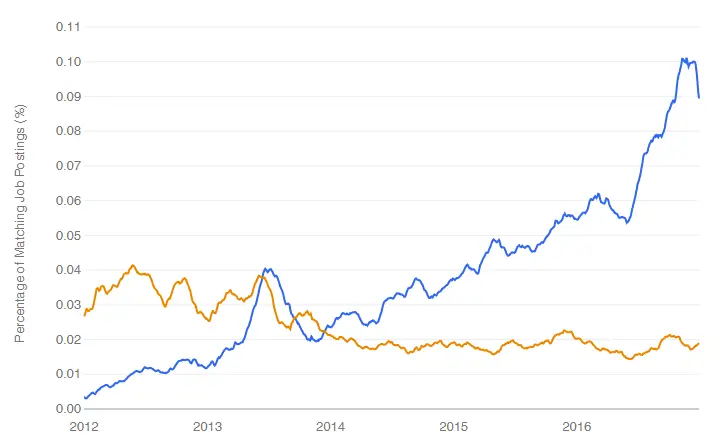
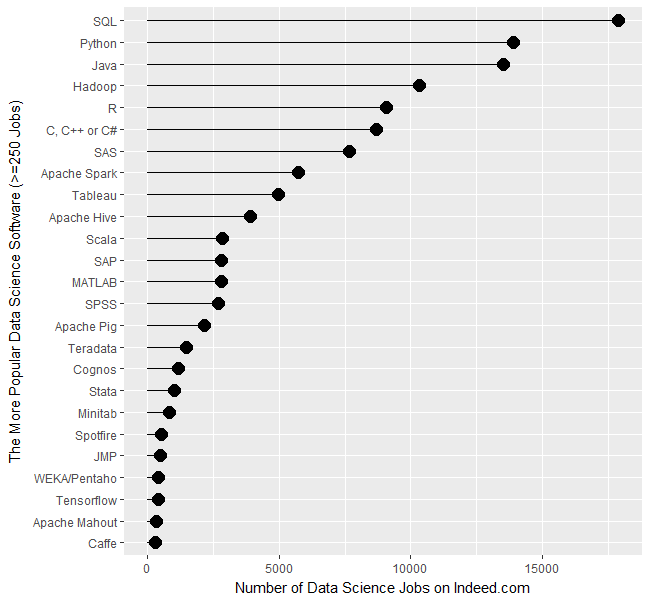
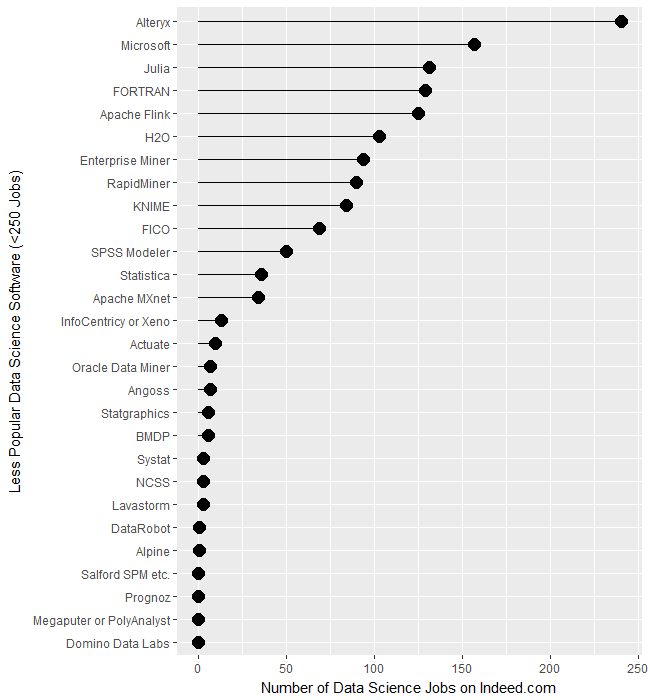
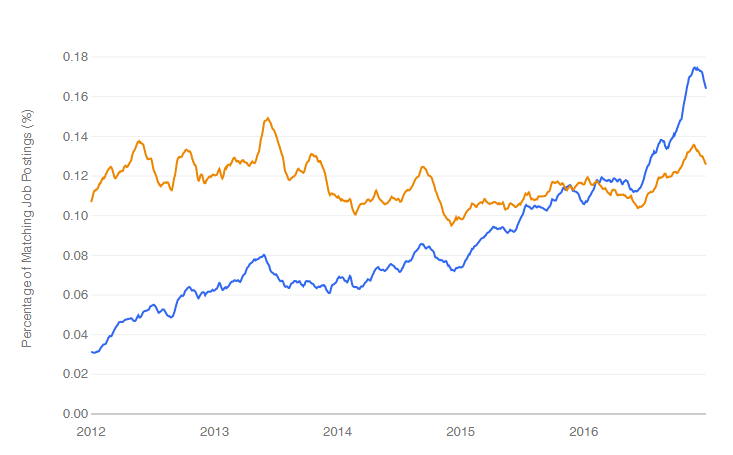
jamovi is software that aims to simplify two aspects of using R. It offers a point-and-click graphical user interface (GUI). It also provides functions that combines the capabilities of many others, bringing a more SPSS- or SAS-like method of programming to R.
The ideal researcher would be an expert at their chosen field of study, data analysis, and computer programming. However, staying good at programming requires regular practice, and data collection on each project can take months or years. GUIs are ideal for people who only analyze data occasionally, since they only require you to recognize what you need in menus and dialog boxes, rather than having to recall programming statements from memory. This is likely why GUI-based research tools have been widely used in academic research for many years.
Several attempts have been made to make the powerful R language accessible to occasional users, including R Commander, Deducer, Rattle, and Bluesky Statistics. R Commander has been particularly successful, with over 40 plug-ins available for it. As helpful as those tools are, they lack the key element of reproducibility (more on that later).
jamovi’s developers designed its GUI to be familiar to SPSS users. Their goal is to have the most widely used parts of SPSS implemented by August of 2018, and they are well on their way. To use it, you simply click on Data>Open and select a comma separate values file (other formats will be supported soon). It will guess at the type of data in each column, which you can check and/or change by choosing Data>Setup and picking from: Continuous, Ordinal, Nominal, or Nominal Text.
Alternately, you could enter data manually in jamovi’s data editor. It accepts numeric, scientific notation, and character data, but not dates. Its default format is numeric, but when given text strings, it converts automatically to Nominal Text. If that was a typo, deleting it converts it immediately back to numeric. I missed some features such as finding data values or variable names, or pinning an ID column in place while scrolling across columns.
To analyze data, you click on jamovi’s Analysis tab. There, each menu item contains a drop-down list of various popular methods of statistical analysis. In the image below, I clicked on the ANOVA menu, and chose ANOVA to do a factorial analysis. I dragged the variables into the various model roles, and then chose the options I wanted. As I clicked on each option, its output appeared immediately in the window on the right. It’s well established that immediate feedback accelerates learning, so this is much better than having to click “Run” each time, and then go searching around the output to see what changed.
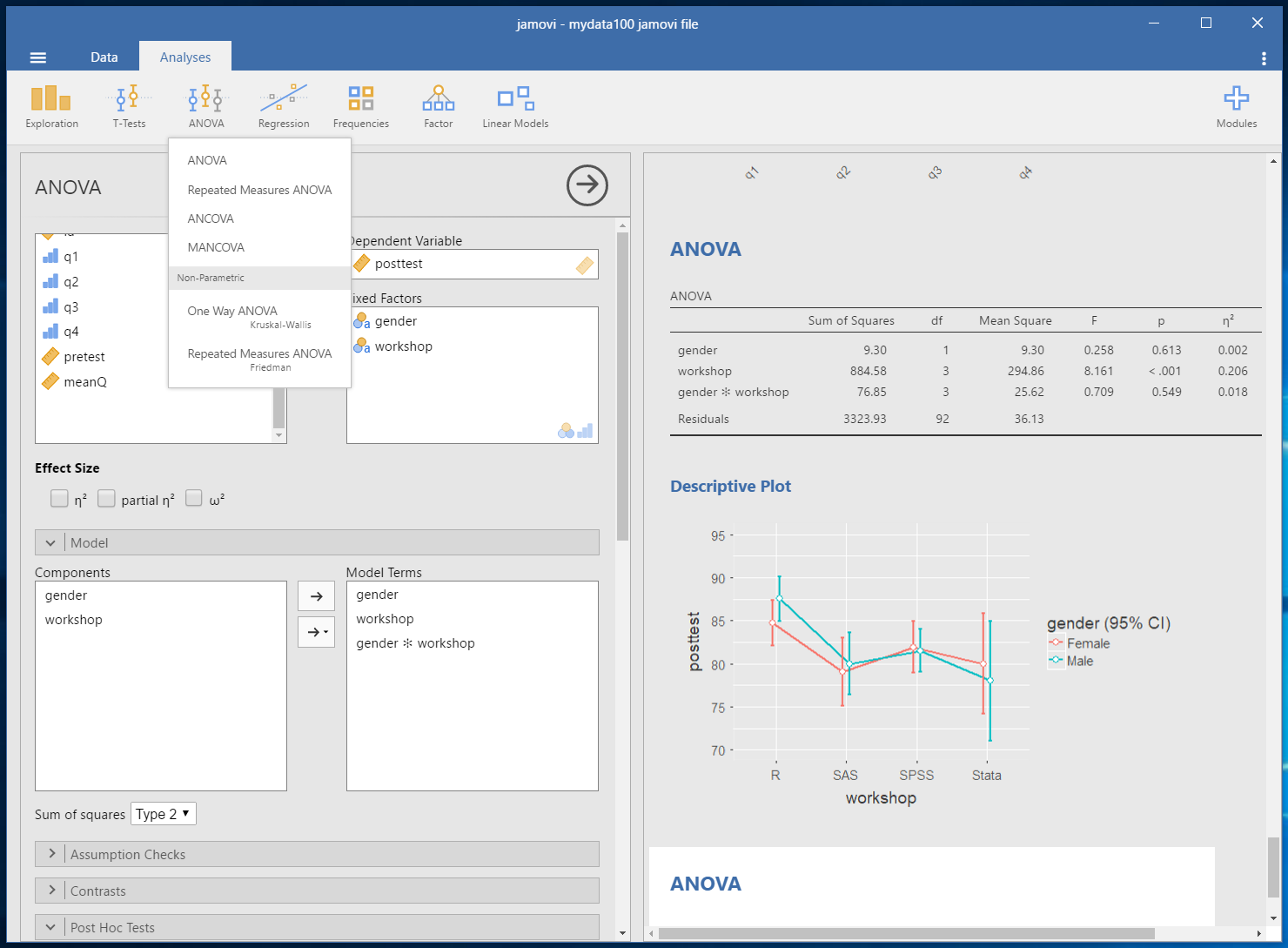
The tabular output is done in academic journal style by default, and when pasted into Microsoft Word, it’s a table object ready to edit or publish:
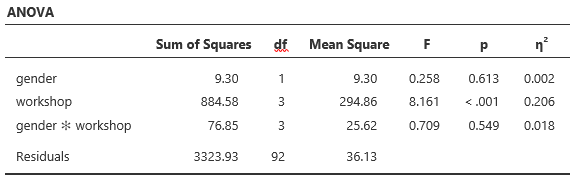
You have the choice of copying a single table or graph, or a particular analysis with all its tables and graphs at once. Here’s an example of its graphical output:
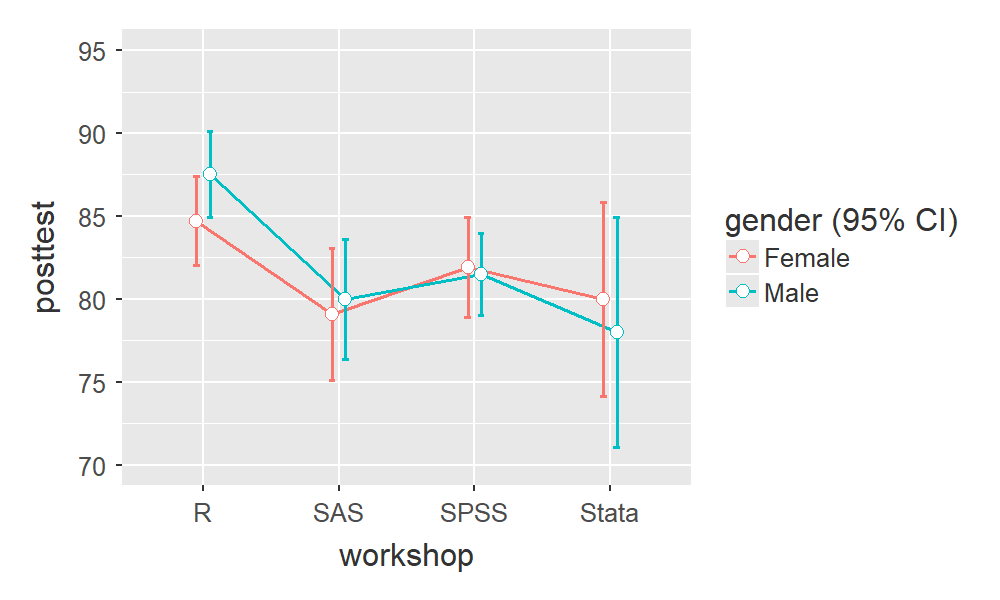
jamovi offers four styles for graphics: default a simple one with plain background, minimal which – oddly enough – adds a grid at the major tick-points; I♥SPSS, which copies the look of that software; and Hadley, which follows the style of Hadley Wickham’s popular ggplot2 package.
At the moment, nearly all graphs are produced through analyses. A set of graphics menus is in the works. I hope the developers will be able to offer full control over custom graphics similar to Ian Fellows’ powerful Plot Builder used in his Deducer GUI.
The graphical output looks fine on a computer screen, but when using copy-paste into Word, it is a fairly low-resolution bitmap. To get higher resolution images, you must right click on it and choose Save As from the menu to write the image to SVG, EPS, or PDF files. Windows users will see those options on the usual drop-down menu, but a bug in the Mac version blocks that. However, manually adding the appropriate extension will cause it to write the chosen format.
jamovi offers full reproducibility, and it is one of the few menu-based GUIs to do so. Menu-based tools such as SPSS or R Commander offer reproducibility via the programming code the GUI creates as people make menu selections. However, the settings in the dialog boxes are not currently saved from session to session. Since point-and-click users are often unable to understand that code, it’s not reproducible to them. A jamovi file contains: the data, the dialog-box settings, the syntax used, and the output. When you re-open one, it is as if you just performed all the analyses and never left. So if your data collection process came up with a few more observations, or if you found a data entry error, making the changes will automatically recalculate the analyses that would be affected (and no others).
While jamovi offers reproducibility, it does not offer reusability. Variable transformations and analysis steps are saved, and can be changed, but the data input data set cannot be changed. This is tantalizingly close to full reusability; if the developers allowed you to choose another data set (e.g. apply last week’s analysis to this week’s data) it would be a powerful and fairly unique feature. The new data would have to contain variables with the same names, of course. At the moment, only workflow-based GUIs such as KNIME offer re-usability in a graphical form.
As nice as the output is, it’s missing some very important features. In a complex analysis, it’s all too easy to lose track of what’s what. It needs a way to change the title of each set of output, and all pieces of output need to be clearly labeled (e.g. which sums of squares approach was used). The output needs the ability to collapse into an outline form to assist in finding a particular analysis, and also allow for dragging the collapsed analyses into a different order.
Another output feature that would be helpful would be to export the entire set of analyses to Microsoft Word. Currently you can find Export>Results under the main “hamburger” menu (upper left of screen). However, that saves only PDF and HTML formats. While you can force Word to open the HTML document, the less computer-savvy users that jamovi targets may not know how to do that. In addition, Word will not display the graphs when the output is exported to HTML. However, opening the HTML file in a browser shows that the images have indeed been saved.
Behind the scenes, jamovi’s menus convert its dialog box settings into a set of function calls from its own jmv package. The calculations in these functions are borrowed from the functions in other established packages. Therefore the accuracy of the calculations should already be well tested. Citations are not yet included in the package, but adding them is on the developers’ to-do list.
If functions already existed to perform these calculations, why did jamovi’s developers decide to develop their own set of functions? The answer is sure to be controversial: to develop a version of the R language that works more like the SPSS or SAS languages. Those languages provide output that is optimized for legibility rather than for further analysis. It is attractive, easy to read, and concise. For example, to compare the t-test and non-parametric analyses on two variables using base R function would look like this:
> t.test(pretest ~ gender, data = mydata100) Welch Two Sample t-test data: pretest by gender t = -0.66251, df = 97.725, p-value = 0.5092 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -2.810931 1.403879 sample estimates: mean in group Female mean in group Male 74.60417 75.30769 > wilcox.test(pretest ~ gender, data = mydata100) Wilcoxon rank sum test with continuity correction data: pretest by gender W = 1133, p-value = 0.4283 alternative hypothesis: true location shift is not equal to 0 > t.test(posttest ~ gender, data = mydata100) Welch Two Sample t-test data: posttest by gender t = -0.57528, df = 97.312, p-value = 0.5664 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -3.365939 1.853119 sample estimates: mean in group Female mean in group Male 81.66667 82.42308 > wilcox.test(posttest ~ gender, data = mydata100) Wilcoxon rank sum test with continuity correction data: posttest by gender W = 1151, p-value = 0.5049 alternative hypothesis: true location shift is not equal to 0
While the same comparison using the jamovi GUI, or its jmv package, would look like this:

Behind the scenes, the jamovi GUI was executing the following function call from the jmv package. You could type this into RStudio to get the same result:
library("jmv")
ttestIS(
data = mydata100,
vars = c("pretest", "posttest"),
group = "gender",
mann = TRUE,
meanDiff = TRUE)
In jamovi (and in SAS/SPSS), there is one command that does an entire analysis. For example, you can use a single function to get: the equation parameters, t-tests on the parameters, an anova table, predicted values, and diagnostic plots. In R, those are usually done with five functions: lm, summary, anova, predict, and plot. In jamovi’s jmv package, a single linReg function does all those steps and more.
The impact of this design is very significant. By comparison, R Commander’s menus match R’s piecemeal programming style. So for linear modeling there are over 25 relevant menu choices spread across the Graphics, Statistics, and Models menus. Which of those apply to regression? You have to recall. In jamovi, choosing Linear Regression from the Regression menu leads you to a single dialog box, where all the choices are relevant. There are still over 20 items from which to choose (jamovi doesn’t do as much as R Commander yet), but you know they’re all useful.
jamovi has a syntax mode that shows you the functions that it used to create the output (under the triple-dot menu in the upper right of the screen). These functions come with the jmv package, which is available on the CRAN repository like any other. You can use jamovi’s syntax mode to learn how to program R from memory, but of course it uses jmv’s all-in-one style of commands instead of R’s piecemeal commands. It will be very interesting to see if the jmv functions become popular with programmers, rather than just GUI users. While it’s a radical change, R has seen other radical programming shifts such as the use of the tidyverse functions.
jamovi’s developers recognize the value of R’s piecemeal approach, but they want to provide an alternative that would be easier to learn for people who don’t need the additional flexibility.
As we have seen, jamovi’s approach has simplified its menus, and R functions, but it offers a third level of simplification: by combining the functions from 20 different packages (displayed when you install jmv), you can install them all in a single step and control them through jmv function calls. This is a controversial design decision, but one that makes sense to their overall goal.
Extending jamovi’s menus is done through add-on modules that are stored in an online repository called the jamovi Library. To see what’s available, you simply click on the large “+ Modules” icon at the upper right of the jamovi window. There are only nine available as I write this (2/12/2018) but the developers have made it fairly easy to bring any R package into the jamovi Library. Creating a menu front-end for a function is easy, but creating publication quality output takes more work.
A limitation in the current release is that data transformations are done one variable at a time. As a result, setting measurement level, taking logarithms, recoding, etc. cannot yet be done on a whole set of variables. This is on the developers to-do list.
Other features I miss include group-by (split-file) analyses and output management. For a discussion of this topic, see my post, Group-By Modeling in R Made Easy.
Another feature that would be helpful is the ability to correct p-values wherever dialog boxes encourage multiple testing by allowing you to select multiple variables (e.g. t-test, contingency tables). R Commander offers this feature for correlation matrices (one I contributed to it) and it helps people understand that the problem with multiple testing is not limited to post-hoc comparisons (for which jamovi does offer to correct p-values).
Though only at version 0.8.1.2.0, I only found only two minor bugs in quite a lot of testing. After asking for post-hoc comparisons, I later found that un-checking the selection box would not make them go away. The other bug I described above when discussing the export of graphics. The developers consider jamovi to be “production ready” and a number of universities are already using it in their undergraduate statistics programs.
In summary, jamovi offers both an easy to use graphical user interface plus a set of functions that combines the capabilities of many others. If its developers, Jonathan Love, Damian Dropmann, and Ravi Selker, complete their goal of matching SPSS’ basic capabilities, I expect it to become very popular. The only skill you need to use it is the ability to use a spreadsheet like Excel. That’s a far larger population of users than those who are good programmers. I look forward to trying jamovi 1.0 this August!
Acknowledgements
Thanks to Jonathon Love, Josh Price, and Christina Peterson for suggestions that significantly improved this post.