Point-and-click graphical user interfaces (GUIs) for R allow people to analyze data using the R software, without having to learn how to program in the R language. This is a brief look at how popular each one is. Knowing that a GUI is popular doesn’t mean it will meet your needs, but it does mean that it’s meeting the needs of many others. This may be helpful information when selecting the appropriate GUI for you, if programming is not your primary interest. For detailed information regarding what each GUI can do for you, and how it works, see my series of comparative reviews, which is currently in progress.
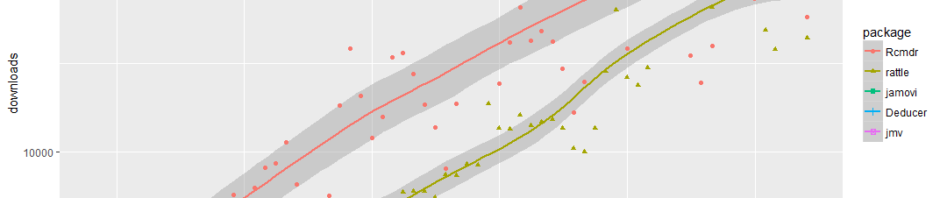
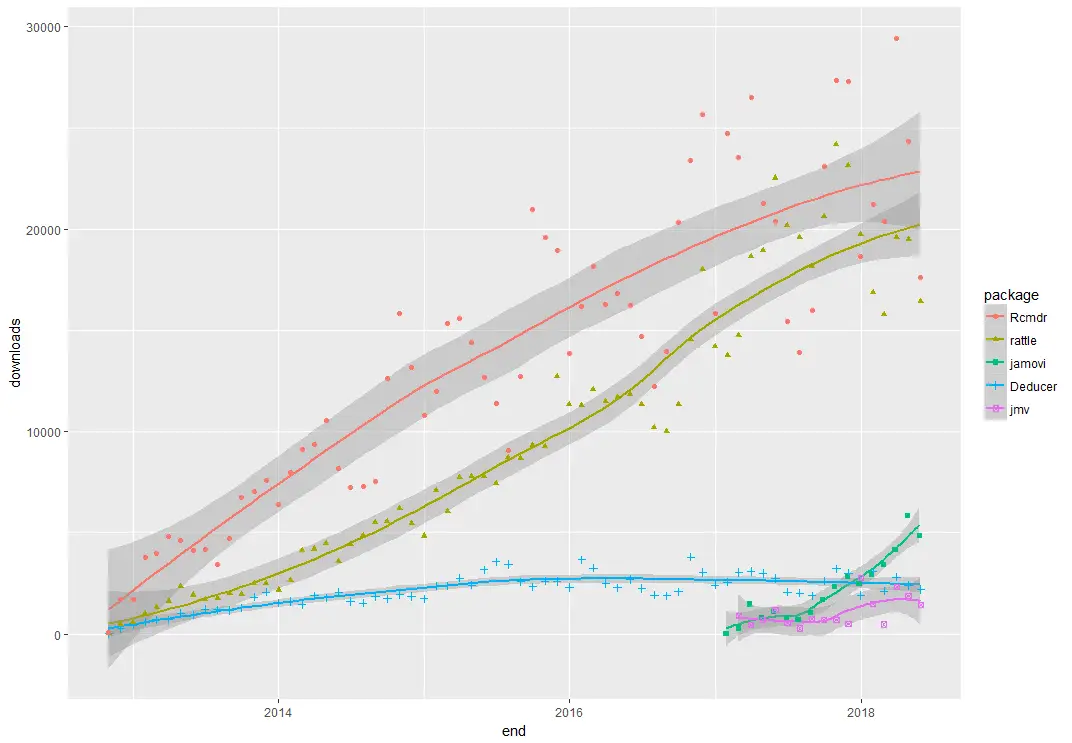
There are many ways to estimate the popularity of data science software, but one of the most accurate is by counting the number of downloads (see appendix for details). Figure 1 shows the monthly downloads of four of the six R GUIs that I’m reviewing (i.e. all that exist as far as I know). We can see that the R Commander (Rcmdr) is the most popular GUI, and it has had steady growth since its introduction. Next comes Rattle, which is more oriented towards machine learning tasks. It too, has shown high popularity and steady growth.
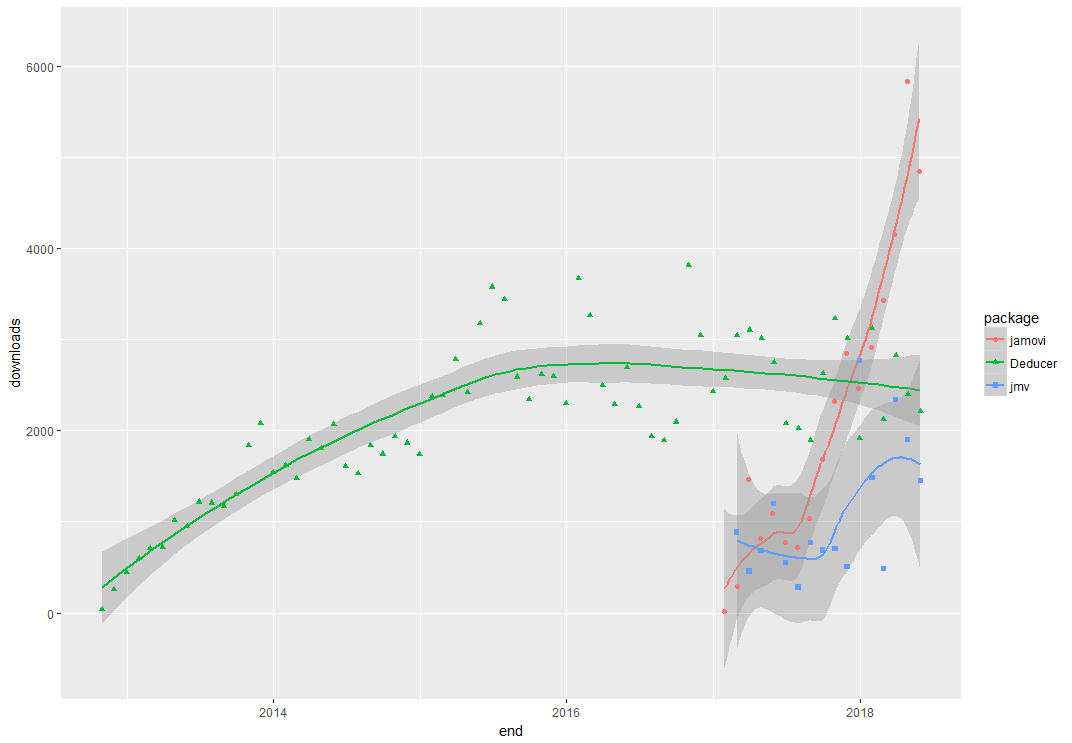
The three lines at the bottom could use more “breathing room” so let’s look at them in their own plot.
Figure 1. Number of times each software was downloaded by month.
Figure 2 shows the same data as Figure 1, but with the two most popular GUIs removed to make room to study the remaining data. From it we can see that Deducer has been around for many more years than the other two. Downloads for Deducer grew steadily for a couple of years, then they leveled off. Its downloads appear to be declining slightly in recent years. jamovi (its name is not capitalized) has only been around for a brief period, and its growth has been very rapid. As you can see from my recent review, jamovi has many useful features.
Figure 2. Number of times the less popular GUIs were downloaded. (Same as Fig. 1, with the R Commander and rattle removed).
The lowest (blue) line shows downloads for the jmv package, that contains all the functions used by the jamovi GUI. It allows programmers to write code instead of using the jamovi GUI. People who point-and-click their way through an analysis in jamovi can send their code to any R user, who would then use the jmv package to run it. Since most jamovi users would prefer to point-and-click their way through analyses, it makes sense that the jmv package has been downloaded many fewer times than jamovi itself.
Two GUIs are missing from this plot: RKWard and BlueSky Statistics. Neither of those are downloaded from CRAN, and I was unable to obtain data from the developers of those GUIs. However, knowing that RKWard has a similar number of point-and-click features as Deducer, one can deduce (heh!) that it might have a similar level of popularity. The BlueSky software has only recently appeared on the scene, especially with its current level of features, so I expect it too will be towards the bottom, but growing rapidly.
I’m nearly done with all my reviews, so stay tuned to see what the other GUIs offer.
Acknowledgements
Thanks to Guangchuang Yu for making the dlstats package which allowed me to collect data so easily. Thanks also to Jonathon Love, who provided the download data for jamovi, and to Josh Price for his helpful editorial advice.
Appendix: Where the Data Came From
I used R’s dlstats package, which makes quick work of gathering counts of monthly downloads of R packages from the Comprehensive R Archive Network (CRAN). CRAN consists of sites around the world called “mirrors” from which people can download R packages. When starting the download process, R asks you to choose a mirror that is close to your location. In the popular RStudio development environment for R, the default mirror is set to their own server, which is actually a worldwide network of mirrors. Since it’s the default download location in a very popular tool for R, its download data will give us a good idea of the relative popularity of each GUI. The absolute popularity will be greater, but to get that data I would have to gather data from all the other servers around the world. If you have time to do that, please send me the results!
RKWard is a free and open source Graphical User Interface for the R software, one that supports beginners looking to point-and-click their way through analyses, as well as advanced programmers. You can think of it as a blend of the menus and dialog boxes that R Commander offers combined with the programming support that RStudio provides. RKWard is available on Windows, Mac, and Linux.
This review is one of a series which aims to help non-programmers choose the Graphical User Interface (GUI) that is best for them. However, I do include a cursory overview of how RKWard helps you work with code. In most sections, I’ll begin with a brief description of the topic’s functionality and how GUIs differ in implementing it. Then I’ll cover how RKWard does it.
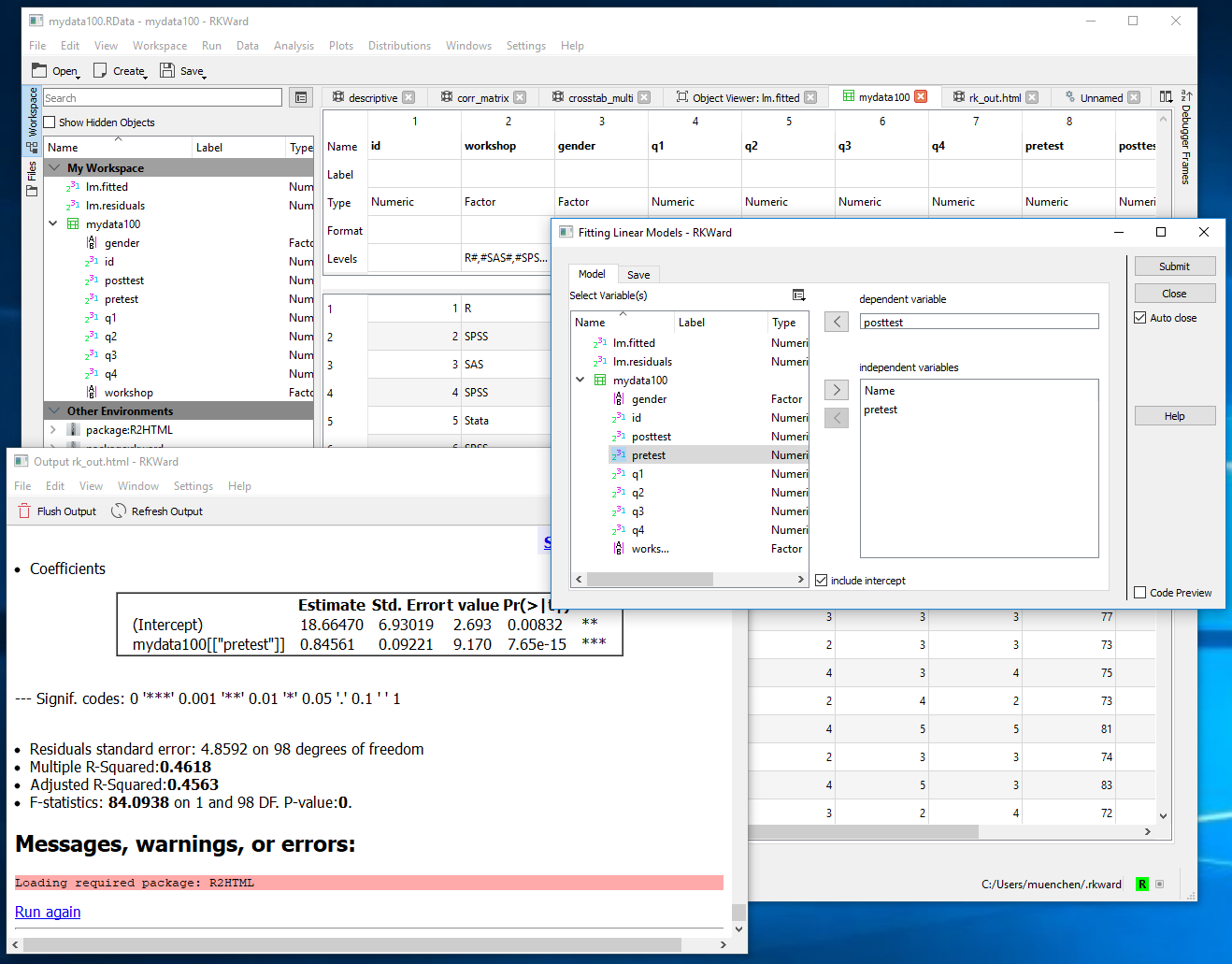
Figure 1. RKWard’s main control screen containing an open data editor window (big one), an open dialog box (right) and its output window (lower left).
Terminology
There are various definitions of user interface types, so here’s how I’ll be using these terms:
GUI = Graphical User Interface specifically using menus and dialog boxes to avoid having to type programming code. I do not include any assistance for programming in this definition. So GUI users are people who prefer using a GUI to perform their analyses. They often don’t have the time required to become good programmers.
IDE = Integrated Development Environment which helps programmers write code. I do not include point-and-click style menus and dialog boxes when using this term. IDE users are people who prefer to write R code to perform their analyses.
Installation
The various user interfaces available for R differ quite a lot in how they’re installed. Some, such as jamovi or BlueSky Statistics, install in a single step. Others install in multiple steps, such as R Commander and Deducer. Advanced computer users often don’t appreciate how lost beginners can become while attempting even a single-step installation. I work at the University of Tennessee, and our HelpDesk is flooded with such calls at the beginning of each semester!
Installing RKWard on Windows is done in a single step since its installation file contains both R and RKWard. However, Mac and Linux users have a two-step process, installing R first, then download RKWard which links up to the most recent version of R that it finds. Regardless of their operating system, RKWard users never need to learn how to start R, then execute the install.packages function, and then load a library. Installers for all three operating systems are available here.
The RKWard installer obtains the appropriate version of R, simplifying the installation and ensuring complete compatibility. However, if you already had a copy of R installed, depending on its version, you could end up with a second copy.
RKWard minimizes the size of its download by waiting to install some R packages until you actually try to use them for the first time. Then it prompts you, offering default settings that will get the package you need.
On Windows, the installation file is 136 megabytes in size.
Plug-ins
When choosing a GUI, one of the most fundamental questions is: what can it do for you? What the initial software installation of each GUI gets you is covered in the Graphics, Analysis, and Modeling section of this series of articles. Regardless of what comes built-in, it’s good to know how active the development community is. They contribute “plug-ins” which add new menus and dialog boxes to the GUI. This level of activity ranges from very low (RKWard, BlueSky, Deducer) through moderate (jamovi) to very active (R Commander).
Currently all plug-ins are included with the initial installation. You can see them using the menu selection Settings> Configure Packages> Manage RKWard Plugins. There are only brief descriptions of what they do, but once installed, you can access the help files with a single click.
RKWard add-on modules are part of standard R packages and are distributed on CRAN. Their package descriptions include a field labeled, “enhances: rkward”. You can sort packages by that field in RKWard’s package installation dialog where they are displayed with the RKWard icon.
Web-based surveys offer a quick and effective way to collect data. Several companies sell software-as-a-service which makes the construction of surveys quite easy using only a web browser. At the University of Tennessee, we currently have a system-wide site license for Qualtrics. Initial discussions suggested an intent from Qualtrics to more than double its price from the previous year. This article describes the process we followed to evaluate and select an alternative, in the interest of providing similar functionality at a reasonable cost.
In choosing the options to review, our first step was to search for online software reviews of tools that we knew were already in use by various groups across all UT campuses and institutes. If one of those provided similar features at a lower price, we could minimize our training and migration expenses. A summary of the reviews’ overall ratings is shown in Table 1.
Table 1. Summary of web survey ratings from online review sites. Some scores are rescaled to range from 1 through 5. While most scores are available directly from the Source link, to get a score on the Comparisons site you must first choose a comparison of two products, then click on one of them to get its full review.
The tools were all highly rated, but we wondered if the raters needed as many features as we use for academic research. A search using Google Scholar confirmed that these were the five survey tools most widely used in scholarly research.
We read all we could find regarding the financial state of each company, read about what employees said about them on Glassdoor.com, and searched for complaints of any sort regarding the companies or their products. We found no significant problems in any of those areas. The companies all seem to be growing quite rapidly.
We also considered using open source software. However, the most popular open source web survey tool is LimeSurvey, and our previous experience with it was not positive. We investigated reviews of LimeSurvey to see if it had improved since we used it last, but there were very few of them compared to the others.
Selection Process
We formed a committee of ten university faculty and staff, all with substantial survey design expertise. The committee compiled a list of 141 web survey features that we considered important. We then surveyed the university research community, including our current survey tool users, asking them to rate the importance of each feature on a 5-point Likert scale. The detailed table of features and importance ratings appears in the appendix.
We used the features list to write the specifications for a Request for Qualified Suppliers (RFQ-S), a type of Request for Proposal. We specified a 5-year contract including separate pricing for: individuals, groups (e.g. departments, colleges, or institutes), single campus, and multi-campuses; as well as internal use, external use with not-for-profit clients, and external use with for-profit clients.
External use is important because the University of Tennessee is a Carnegie Engaged University, which means one of its prime goals is to perform collaborative research with external organizations. The for-profit category was included because students like to solve the types of problems that companies provide. Our Institute for Public Service also occasionally does surveys for companies in Tennessee. Such use is often prohibited from academic software licenses.
The RFQ-S was sent to the five vendors shown in Table 1. To keep things comparable, REDcap Cloud was chosen as the vendor for REDcap. They offer the same type of software-as-a-service as the other venders, though REDcap is also available for on-premises installations for free.
The bids we received covered an extremely wide range, with the highest price more than ten times larger than the lowest. Each of the responding vendors specified which of the 141 features they offered. Only one vendor, Qualtrics, stated that it was not acceptable to use their software for the benefit of any type of external organizations. Qualtrics requires an expensive commercial license when third parties are involved.
We then tested each feature, verifying the companies’ claims. We considered rating each for ease-of-use and effectiveness, but found that if the feature was implemented at all, it was generally both easy to use and effective.
We then created a composite score which weighted each feature according to the ratings from the feature importance survey. Our purchasing department prefers 1,000-point scales, so we adjusted the scores accordingly. A perfect score of 1,000 would indicate software that offered every feature that a demanding person would describe as Very Important. The resulting scores are shown in Table 2. Readers can use the data in the appendix to develop their own scores. Since REDcap Cloud did not respond to our bid, we did not evaluate or score it. However, does offer an extensive feature set including some very advanced features for database use and clinical trials. We are already using the free on-site version for projects that require those features, but it’s not as easy to use as the other products.
Qualtrics
QuestionPro
SurveyGizmo
SurveyMonkey
Total number
of features
(out of 141)
134
132
130
111
Raw Score
541
529
524
456
Scaled score
(x 1.418)
767
750
744
647
Table 2. Feature counts and scores weighted by feature importance. Each feature is listed in the appendix. See vendors for pricing.
QuestionPro and SurveyGizmo offered nearly identical feature sets to Qualtrics, with equivalent ease-of-use, at significantly lower prices. SurveyMonkey offered a smaller set of features, at a price that was much lower than Qualtrics, but still much higher than the others.
We called the three references that QuestionPro and SurveyGizmo had each provided. They all reported that the software worked well, had close to zero downtime, had technical support that was quick and competent, and they all reported planning to continue using their chosen vendor well into the future.
QuestionPro not only scored the highest on the 141 attributes we initially focused on, but it also currently offers advanced features that we had not even considered. The company’s future features roadmap is substantially more advanced than any other product currently on the market, and anything we heard regarding the other vendors’ future plans. As a result, we decided to go with QuestionPro.
Migration Issues
We have changed web survey tools twice before, so we are well aware of the challenges involved. When moving to a new software platform, the software cost is important, but so are migration costs. For example, if we were to attempt a migration from SAS to R in one year’s time, the cost to train people and convert tens of thousands of programs would far outweigh the savings (at least at educational prices). However, survey software is relatively easy to learn, taking an hour to learn how to set up a typical survey. We estimate that a typical survey could be migrated in well under an hour. Complex ones might take much longer, especially those that must migrate longitudinal data along with the survey.
The Qualtrics administrative dashboard allows us to download extensive details about how our people have used the software over the last five years. The total number of accounts is intimidating, at just over 11,000. However, thousands of accounts contain only a single survey with a single response, indicating that the person was simply trying the software out. Thousands more accounts have not been logged into in years. We learned that 80% of surveys each year are created by new users who are starting from scratch and thus have no work to migrate.
We have developed preliminary estimates of migration effort from current usage, and they range between a total of 1,000 and 4,000 hours. Our support staff will be available to help users migrate their projects. We are developing a survey to get more details from current users to better assess migration needs. This will allow us to determine the number of projects that entail additional complexity such as multi-institutional collaboration or longitudinal studies that must maintain long-term data compatibility. We will also be recording the time it takes to move surveys and data to the new system. As we collect such data, we will be able to forecast how long the migration will take.
Conclusion
Our work resulted in the selection of a software package, QuestionPro, which is comparable to Qualtrics at a much lower price. Comparing our final expenditure to the initial price increase that our Qualtrics sales rep requested, the savings over the 5-year life of the contract is over $900,000. In addition, we now have a product that members of the university community can use to solve problems for companies, helping to engage UT more fully into the economy of Tennessee.
If you found this post useful, I invite you to check out many more on my website or follow me on Twitter.
Appendix: Web survey tool features and their importance ratings
The importance of each feature (1=very low importance…5= very important) was determined by current users of web survey tools at the University of Tennessee. A rating of zero indicates that the software lacks that feature. This information was current as of 12/1/2017; the vendors all regularly add new features so check their web sites for their latest information.
Feature
Qualtrics
QuestionPro
SurveyGizmo
SurveyMonkey
Display Text (e.g. instructions)
4.46
4.46
4.46
4.46
Skip Logic
4.65
4.65
4.65
4.65
Display Logic
4.65
4.65
4.65
4.65
Required Questions / Required Answers
4.64
4.64
4.64
4.64
Redirect Browser at end of survey
3.83
3.83
3.83
3.83
Anonymous Responses (separate survey data from distribution/contact information)
4.51
4.51
4.51
4.51
Embedded Data/Hidden Values/Custom Values
3.85
3.85
3.85
3.85
Survey Collaboration
4.51
4.51
4.51
4.51
Single Response
4.68
4.68
4.68
4.68
Multiple Response
4.70
4.70
4.70
4.70
Likert Grid/Matrix
4.60
4.60
4.60
4.60
Open-ended text
4.60
4.60
4.60
4.60
Email distribution
4.72
4.72
4.72
4.72
Contact Management
4.50
4.50
4.50
4.50
Send Reminders
4.57
4.57
4.57
4.57
Export to CSV
4.69
4.69
4.69
4.69
Export to at least one statistics package (such as SAS, SPSS…)
4.51
4.51
4.51
4.51
SSO login
4.51
4.51
4.51
4.51
Phone Support (for users and admins)
4.51
4.51
4.51
4.51
Integrated Question Design Methodology Advice
0.00
0.00
0.00
3.96
Machine Learning to Improve Response Rate
0.00
3.84
0.00
3.84
Randomization of Questions
3.71
3.71
3.71
3.71
Randomization of Responses
3.57
3.57
3.57
3.57
A/B Test Questions (Split respondents between scenarios)
3.82
3.82
3.82
3.82
Multi-Lingual Surveys
3.68
3.68
3.68
3.68
Quiz Development
3.74
3.74
3.74
3.74
Score Survey
3.89
3.89
3.89
3.89
Custom Survey Templates
4.23
4.23
4.23
4.23
Branch Logic
4.62
4.62
4.62
4.62
Preview Survey for Standard Screen Size
4.58
4.58
4.58
4.58
Preview Survey for Phone Screen Size
4.58
4.58
4.58
4.58
Easy to Create Interface
3.95
3.95
3.95
3.95
Recode Values/Set Reporting Values (i.e. set Yes to 1 and No to 0 or recode on an unsual scale such as 0,1,3,5)
4.16
4.16
4.16
4.16
Custom Javascript Support
3.59
3.59
3.59
0.00
Loop&Merge / Page Piping (loop through the same set of questions a given number of times)
3.94
3.94
3.94
3.94
Insert Piped Text from question or custom value into question text
4.02
4.02
4.02
4.02
Insert Piped Text from question or custom value into question response
3.95
3.95
3.95
3.95
Carry Forward selected answers to populate future questions
4.11
4.11
4.11
4.11
Carry Forward response choices to populate responses on future questions
4.10
4.10
4.10
0.00
Soft-Require Question (request response)
4.41
4.41
4.41
0.00
Optional Progress Bar
4.21
4.21
4.21
4.21
API Integration
3.89
3.89
3.89
3.89
GoogleForm Integration
0.00
3.82
0.00
3.82
Email Triggers/Action Alerts (trigger emails automatically to be sent based on survey responses)
4.17
4.17
4.17
4.17
Contact List Triggers (add people to contact list automatically based on how they answer a survey)
3.98
3.98
0.00
0.00
Edit Next, Submit and Close Button Text
4.23
4.23
4.23
4.23
Hide Next, Submit or Close buttons
4.03
4.03
4.03
0.00
File Library
4.08
4.08
4.08
4.08
Import Surveys Questions from Word
0.00
4.28
4.28
4.28
Export Survey Questions to Word
4.39
4.39
4.39
0.00
Import/Export Survey file (to create a copy that can be exported/imported)
4.61
4.61
4.61
4.61
Copy Survey within survey tool
4.64
4.64
4.64
4.64
Revert to previous versions
4.16
4.16
4.16
0.00
Password/contact list authentication within a survey (respondent must authenticate with credentials saved within the contact list to continue)
3.90
3.90
3.90
3.90
SSO authentication within a survey (respondent must authenticate with SSO credentials to continue)
3.78
3.78
3.78
3.78
Connect to Web Services (such as random number generator)
3.79
3.79
3.79
0.00
Survey Collaboration within the university/license/brand
4.30
4.30
4.30
4.30
Survey Collaboration outside of the university/license/brand
3.81
0.00
3.81
3.81
Numeric Entry
4.41
4.41
4.41
4.41
Constant Sum
3.56
3.56
3.56
0.00
Slider
3.63
3.63
3.63
3.63
Ranking
4.19
4.19
4.19
4.19
Descriptive Text/Graphic
4.46
4.46
4.46
4.46
Side by Side
3.99
3.99
3.99
3.99
Captcha
3.01
3.01
3.01
0.00
Signature
3.25
3.25
3.25
0.00
Closed Card Sort Questions
3.08
3.08
3.08
0.00
Image Heatmap Questions
2.88
2.88
2.88
0.00
Open Card Sort Questions
0.00
3.08
3.08
0.00
Semantic Differential Questions
3.28
3.28
3.28
3.28
Text Highlighter Questions
3.53
3.53
3.53
0.00
Choice Based Conjoint
3.35
3.35
3.35
0.00
Max Differential (Max Diff) Questions
3.39
3.39
3.39
0.00
Track Time Respondent Stays on a Question or Page
3.55
3.55
3.55
0.00
Audio/Video Sentiment Questions (slider recording response while video/audio plays)
0.00
3.45
3.45
0.00
File Upload
4.07
4.07
4.07
4.07
Geo-Targeting/Tracking
3.20
3.20
3.20
3.20
Embed External Audio and Video Files
3.81
3.81
3.81
3.81
Real-time Responses
4.13
4.13
4.13
4.13
Filter Responses
4.39
4.39
4.39
4.39
Printed Reports
4.37
4.37
4.37
4.37
Cross-Tabulation Reporting
4.31
4.31
4.31
4.31
Variable Creation
4.20
4.20
0.00
0.00
Response Editing
4.05
4.05
4.05
4.05
View Reports Online
4.67
4.67
4.67
4.67
Export report from within offline report (pdf or other format)
4.51
4.51
4.51
4.51
Import response data from Excel or other format
4.26
4.26
4.26
0.00
Manually enter response data collected externally
4.16
4.16
4.16
4.16
Export reports (Please attach list formats)
4.67
4.67
4.67
4.67
Export Individual Charts
4.39
4.39
4.39
4.39
Create reports from multiple data sources
4.35
4.35
4.35
4.35
Share Contact Lists
4.19
4.19
4.19
4.19
Group organization
4.33
4.33
4.33
4.33
Social Media Distribution
3.88
3.88
3.88
3.88
SMS Distribution
3.60
3.60
0.00
0.00
Template Library of Messages
4.06
4.06
0.00
4.06
Embed First Question in Email Invite
3.29
3.29
3.29
3.29
Mobile First UX
3.95
3.95
3.95
3.95
Response Panels
2.86
2.86
2.86
2.86
URL Shortener
3.91
3.91
3.91
3.91
Survey Quotas
3.43
3.43
3.43
3.43
Schedule email invites and reminders
4.41
4.41
4.41
4.41
Schedule survey to close
4.53
4.53
4.53
4.53
Resend Link after completion
3.31
3.31
3.31
3.31
Send email to Contact List without survey link
3.32
0.00
3.32
3.32
Optional opt out link in emails
4.07
4.07
4.07
4.07
Stand alone Mobile App
4.17
4.17
0.00
4.17
Offline Mode
3.65
3.65
3.65
0.00
SPSS
4.32
4.32
4.32
4.32
PDF
4.31
4.31
4.31
4.31
PowerPoint
3.93
3.93
3.93
3.93
Change variable labels and/or response values before export
4.19
0.00
4.19
4.19
Select if data are exported as Response Text or Response Value
4.37
4.37
4.37
4.37
Export subset of data
4.43
4.43
4.43
4.43
Word Cloud
3.48
3.48
3.48
3.48
Tag Text Themes Manually
3.60
3.60
3.60
3.60
Sentiment Analysis
3.61
3.61
0.00
0.00
Nvivo Integration
3.77
0.00
3.77
3.77
Automatic Tagging
3.56
0.00
3.56
0.00
Admin Dashboard
3.95
3.95
3.95
3.95
Ability to log into user account through Admin account
I’ve just updated The Popularity of Data Science Software to reflect my take on Gartner’s 2018 report, Magic Quadrant for Data Science and Machine Learning Platforms. To save you the trouble of digging though all 40+ pages of my report, here’s just the new section:
IT Research Firms
IT research firms study software products and corporate strategies, they survey customers regarding their satisfaction with the products and services, and then provide their analysis on each in reports they sell to their clients. Each research firm has its own criteria for rating companies, so they don’t always agree. However, I find the detailed analysis that these reports contain extremely interesting reading. While these reports focus on companies, they often also describe how their commercial tools integrate open source tools such as R, Python, H2O, TensoFlow, and others.
While these reports are expensive, the companies that receive good ratings usually purchase copies to give away to potential customers. An Internet search of the report title will often reveal the companies that are distributing such free copies.
Gartner, Inc. is one of the companies that provides such reports. Out of the roughly 100 companies selling data science software, Gartner selected 16 which had either high revenue, or lower revenue combined with high growth (see full report for details). After extensive input from both customers and company representatives, Gartner analysts rated the companies on their “completeness of vision” and their “ability to execute” that vision. Hereafter, I refer to these as simply vision and ability. Figure 3a shows the resulting “Magic Quadrant” plot for 2018, and 3b shows the plot for the previous year.
The Leader’s Quadrant is the place for companies who have a future direction in line with their customer’s needs and the resources to execute that vision. The further to the upper-right corner, the better the combined score. KNIME is in the prime position, with H2O.ai showing greater vision but lower ability to execute. This year KNIME gained the ability to run H2O.ai algorithms, so these two may be viewed as complementary tools rather than outright competitors.
Alteryx and SAS have nearly the same combined scores, but note that Gartner studied only SAS Enterprise Miner and SAS Visual Analytics. The latter includes Visual Statistics, and Visual Data Mining and Machine Learning. Excluded was the SAS System itself since Gartner focuses on tools that are integrated. This lack of integration may explain SAS’ decline in vision from last year.
KNIME and RapidMiner are quite similar tools as they are both driven by an easy to use and reproducible workflow interface. Both offer free and open source versions, but the companies differ quite a lot on how committed they are to the open source concept. KNIME’s desktop version is free and open source and the company says it will always be so. On the other hand, RapidMiner is limited by a cap on the amount of data that it can analyze (10,000 cases) and as they add new features, they usually come only via a commercial license. In the previous year’s Magic Quadrant, RapidMiner was slightly ahead, but now KNIME is in the lead.
Figure 3a. Gartner Magic Quadrant for Data Science and Machine Learning PlatformsFigure 3b. Gartner Magic Quadrant for Data Science Platforms 2017.
The companies in the Visionaries Quadrant are those that have a good future plans but which may not have the resources to execute that vision. Of these, IBM took a big hit by landing here after being in the Leader’s Quadrant for several years. Now they’re in a near-tie with Microsoft and Domino. Domino shot up from the bottom of that quadrant to towards the top. They integrate many different open source and commercial software (e.g. SAS, MATLAB) into their Domino Data Science Platform. Databricks and Dataiku offer cloud-based analytics similar to Domino, though lacking in access to commercial tools.
Those in the Challenger’s Quadrant have ample resources but less customer confidence on their future plans, or vision. Mathworks, the makers of MATLAB, continues to “stay the course” with its proprietary tools while most of the competition offers much better integration into the ever-expanding universe of open source tools. Tibco replaces Quest in this quadrant due to their purchase of Statistica. Whatever will become of the red-headed stepchild of data science? Statistica has been owned by four companies in four years! (Statsoft, Dell, Quest, Tibco) Users of the software have got to be considering other options. Tibco also purchased Alpine Data in 2017, accounting for its disappearance from Figure 3b to 3a.
Members of the Niche Players quadrant offer tools that are not as broadly applicable. Anaconda is new to Gartner coverage this year. It offers in-depth support for Python. SAP has a toolchain that Gartner calls “fragmented and ambiguous.” Angoss was recently purchased by Datawatch. Gartner points out that after 20 years in business, Angoss has only 300 loyal customers. With competition fierce in the data science arena, one can’t help but wonder how long they’ll be around. Speaking of deathwatches, once the king of Big Data, Teradata has been hammered by competition from open source tools such as Hadoop and Spark. Teradata’s net income was higher in 2008 than it is today.
As of 2/26/2018, RapidMiner is giving away copies of the Gartner report here.
[An updated version of this post is located here.]
jamovi is software that aims to simplify two aspects of using R. It offers a point-and-click graphical user interface (GUI). It also provides functions that combines the capabilities of many others, bringing a more SPSS- or SAS-like method of programming to R.
The ideal researcher would be an expert at their chosen field of study, data analysis, and computer programming. However, staying good at programming requires regular practice, and data collection on each project can take months or years. GUIs are ideal for people who only analyze data occasionally, since they only require you to recognize what you need in menus and dialog boxes, rather than having to recall programming statements from memory. This is likely why GUI-based research tools have been widely used in academic research for many years.
Several attempts have been made to make the powerful R language accessible to occasional users, including R Commander, Deducer, Rattle, and Bluesky Statistics. R Commander has been particularly successful, with over 40 plug-ins available for it. As helpful as those tools are, they lack the key element of reproducibility (more on that later).
jamovi’s developers designed its GUI to be familiar to SPSS users. Their goal is to have the most widely used parts of SPSS implemented by August of 2018, and they are well on their way. To use it, you simply click on Data>Open and select a comma separate values file (other formats will be supported soon). It will guess at the type of data in each column, which you can check and/or change by choosing Data>Setup and picking from: Continuous, Ordinal, Nominal, or Nominal Text.
Alternately, you could enter data manually in jamovi’s data editor. It accepts numeric, scientific notation, and character data, but not dates. Its default format is numeric, but when given text strings, it converts automatically to Nominal Text. If that was a typo, deleting it converts it immediately back to numeric. I missed some features such as finding data values or variable names, or pinning an ID column in place while scrolling across columns.
To analyze data, you click on jamovi’s Analysis tab. There, each menu item contains a drop-down list of various popular methods of statistical analysis. In the image below, I clicked on the ANOVA menu, and chose ANOVA to do a factorial analysis. I dragged the variables into the various model roles, and then chose the options I wanted. As I clicked on each option, its output appeared immediately in the window on the right. It’s well established that immediate feedback accelerates learning, so this is much better than having to click “Run” each time, and then go searching around the output to see what changed.
The tabular output is done in academic journal style by default, and when pasted into Microsoft Word, it’s a table object ready to edit or publish:
You have the choice of copying a single table or graph, or a particular analysis with all its tables and graphs at once. Here’s an example of its graphical output:
Interaction plot from jamovi using the “Hadley” style. Note how it offsets the confidence intervals to for each workshop automatically to make them easier to read when they overlap.
jamovi offers four styles for graphics: default a simple one with plain background, minimal which – oddly enough – adds a grid at the major tick-points; I♥SPSS, which copies the look of that software; and Hadley, which follows the style of Hadley Wickham’s popular ggplot2 package.
At the moment, nearly all graphs are produced through analyses. A set of graphics menus is in the works. I hope the developers will be able to offer full control over custom graphics similar to Ian Fellows’ powerful Plot Builder used in his Deducer GUI.
The graphical output looks fine on a computer screen, but when using copy-paste into Word, it is a fairly low-resolution bitmap. To get higher resolution images, you must right click on it and choose Save As from the menu to write the image to SVG, EPS, or PDF files. Windows users will see those options on the usual drop-down menu, but a bug in the Mac version blocks that. However, manually adding the appropriate extension will cause it to write the chosen format.
jamovi offers full reproducibility, and it is one of the few menu-based GUIs to do so. Menu-based tools such as SPSS or R Commander offer reproducibility via the programming code the GUI creates as people make menu selections. However, the settings in the dialog boxes are not currently saved from session to session. Since point-and-click users are often unable to understand that code, it’s not reproducible to them. A jamovi file contains: the data, the dialog-box settings, the syntax used, and the output. When you re-open one, it is as if you just performed all the analyses and never left. So if your data collection process came up with a few more observations, or if you found a data entry error, making the changes will automatically recalculate the analyses that would be affected (and no others).
While jamovi offers reproducibility, it does not offer reusability. Variable transformations and analysis steps are saved, and can be changed, but the data input data set cannot be changed. This is tantalizingly close to full reusability; if the developers allowed you to choose another data set (e.g. apply last week’s analysis to this week’s data) it would be a powerful and fairly unique feature. The new data would have to contain variables with the same names, of course. At the moment, only workflow-based GUIs such as KNIME offer re-usability in a graphical form.
As nice as the output is, it’s missing some very important features. In a complex analysis, it’s all too easy to lose track of what’s what. It needs a way to change the title of each set of output, and all pieces of output need to be clearly labeled (e.g. which sums of squares approach was used). The output needs the ability to collapse into an outline form to assist in finding a particular analysis, and also allow for dragging the collapsed analyses into a different order.
Another output feature that would be helpful would be to export the entire set of analyses to Microsoft Word. Currently you can find Export>Results under the main “hamburger” menu (upper left of screen). However, that saves only PDF and HTML formats. While you can force Word to open the HTML document, the less computer-savvy users that jamovi targets may not know how to do that. In addition, Word will not display the graphs when the output is exported to HTML. However, opening the HTML file in a browser shows that the images have indeed been saved.
Behind the scenes, jamovi’s menus convert its dialog box settings into a set of function calls from its own jmv package. The calculations in these functions are borrowed from the functions in other established packages. Therefore the accuracy of the calculations should already be well tested. Citations are not yet included in the package, but adding them is on the developers’ to-do list.
If functions already existed to perform these calculations, why did jamovi’s developers decide to develop their own set of functions? The answer is sure to be controversial: to develop a version of the R language that works more like the SPSS or SAS languages. Those languages provide output that is optimized for legibility rather than for further analysis. It is attractive, easy to read, and concise. For example, to compare the t-test and non-parametric analyses on two variables using base R function would look like this:
> t.test(pretest ~ gender, data = mydata100)
Welch Two Sample t-test
data: pretest by gender
t = -0.66251, df = 97.725, p-value = 0.5092
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-2.810931 1.403879
sample estimates:
mean in group Female mean in group Male
74.60417 75.30769
> wilcox.test(pretest ~ gender, data = mydata100)
Wilcoxon rank sum test with continuity correction
data: pretest by gender
W = 1133, p-value = 0.4283
alternative hypothesis: true location shift is not equal to 0
> t.test(posttest ~ gender, data = mydata100)
Welch Two Sample t-test
data: posttest by gender
t = -0.57528, df = 97.312, p-value = 0.5664
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-3.365939 1.853119
sample estimates:
mean in group Female mean in group Male
81.66667 82.42308
> wilcox.test(posttest ~ gender, data = mydata100)
Wilcoxon rank sum test with continuity correction
data: posttest by gender
W = 1151, p-value = 0.5049
alternative hypothesis: true location shift is not equal to 0
While the same comparison using the jamovi GUI, or its jmv package, would look like this:
Output from jamovi or its jmv package.
Behind the scenes, the jamovi GUI was executing the following function call from the jmv package. You could type this into RStudio to get the same result:
library("jmv")
ttestIS(
data = mydata100,
vars = c("pretest", "posttest"),
group = "gender",
mann = TRUE,
meanDiff = TRUE)
In jamovi (and in SAS/SPSS), there is one command that does an entire analysis. For example, you can use a single function to get: the equation parameters, t-tests on the parameters, an anova table, predicted values, and diagnostic plots. In R, those are usually done with five functions: lm, summary, anova, predict, and plot. In jamovi’s jmv package, a single linReg function does all those steps and more.
The impact of this design is very significant. By comparison, R Commander’s menus match R’s piecemeal programming style. So for linear modeling there are over 25 relevant menu choices spread across the Graphics, Statistics, and Models menus. Which of those apply to regression? You have to recall. In jamovi, choosing Linear Regression from the Regression menu leads you to a single dialog box, where all the choices are relevant. There are still over 20 items from which to choose (jamovi doesn’t do as much as R Commander yet), but you know they’re all useful.
jamovi has a syntax mode that shows you the functions that it used to create the output (under the triple-dot menu in the upper right of the screen). These functions come with the jmv package, which is available on the CRAN repository like any other. You can use jamovi’s syntax mode to learn how to program R from memory, but of course it uses jmv’s all-in-one style of commands instead of R’s piecemeal commands. It will be very interesting to see if the jmv functions become popular with programmers, rather than just GUI users. While it’s a radical change, R has seen other radical programming shifts such as the use of the tidyverse functions.
jamovi’s developers recognize the value of R’s piecemeal approach, but they want to provide an alternative that would be easier to learn for people who don’t need the additional flexibility.
As we have seen, jamovi’s approach has simplified its menus, and R functions, but it offers a third level of simplification: by combining the functions from 20 different packages (displayed when you install jmv), you can install them all in a single step and control them through jmv function calls. This is a controversial design decision, but one that makes sense to their overall goal.
Extending jamovi’s menus is done through add-on modules that are stored in an online repository called the jamovi Library. To see what’s available, you simply click on the large “+ Modules” icon at the upper right of the jamovi window. There are only nine available as I write this (2/12/2018) but the developers have made it fairly easy to bring any R package into the jamovi Library. Creating a menu front-end for a function is easy, but creating publication quality output takes more work.
A limitation in the current release is that data transformations are done one variable at a time. As a result, setting measurement level, taking logarithms, recoding, etc. cannot yet be done on a whole set of variables. This is on the developers to-do list.
Other features I miss include group-by (split-file) analyses and output management. For a discussion of this topic, see my post, Group-By Modeling in R Made Easy.
Another feature that would be helpful is the ability to correct p-values wherever dialog boxes encourage multiple testing by allowing you to select multiple variables (e.g. t-test, contingency tables). R Commander offers this feature for correlation matrices (one I contributed to it) and it helps people understand that the problem with multiple testing is not limited to post-hoc comparisons (for which jamovi does offer to correct p-values).
Though only at version 0.8.1.2.0, I only found only two minor bugs in quite a lot of testing. After asking for post-hoc comparisons, I later found that un-checking the selection box would not make them go away. The other bug I described above when discussing the export of graphics. The developers consider jamovi to be “production ready” and a number of universities are already using it in their undergraduate statistics programs.
In summary, jamovi offers both an easy to use graphical user interface plus a set of functions that combines the capabilities of many others. If its developers, Jonathan Love, Damian Dropmann, and Ravi Selker, complete their goal of matching SPSS’ basic capabilities, I expect it to become very popular. The only skill you need to use it is the ability to use a spreadsheet like Excel. That’s a far larger population of users than those who are good programmers. I look forward to trying jamovi 1.0 this August!
Acknowledgements
Thanks to Jonathon Love, Josh Price, and Christina Peterson for suggestions that significantly improved this post.
Below is the latest update to The Popularity of Data Science Software. It contains an analysis of the tools used in the most recent complete year of scholarly articles. The section is also integrated into the main paper itself.
New software covered includes: Amazon Machine Learning, Apache Mahout, Apache MXNet, Caffe, Dataiku, DataRobot, Domino Data Labs, GraphPad Prism, IBM Watson, Pentaho, and Google’s TensorFlow.
Software dropped includes: Infocentricity (acquired by FICO), SAP KXEN (tiny usage), Tableau, and Tibco. The latter two didn’t fit in with the others due to their limited selection of advanced analytic methods.
Scholarly Articles
Scholarly articles provide a rich source of information about data science tools. Their creation requires significant amounts of effort, much more than is required to respond to a survey of tool usage. The more popular a software package is, the more likely it will appear in scholarly publications as an analysis tool, or even an object of study.
Since graduate students do the great majority of analysis in such articles, the software used can be a leading indicator of where things are headed. Google Scholar offers a way to measure such activity. However, no search of this magnitude is perfect; each will include some irrelevant articles and reject some relevant ones. Searching through concise job requirements (see previous section) is easier than searching through scholarly articles; however only software that has advanced analytical capabilities can be studied using this approach. The details of the search terms I used are complex enough to move to a companion article, How to Search For Data Science Articles. Since Google regularly improves its search algorithm, each year I re-collect the data for the previous years.
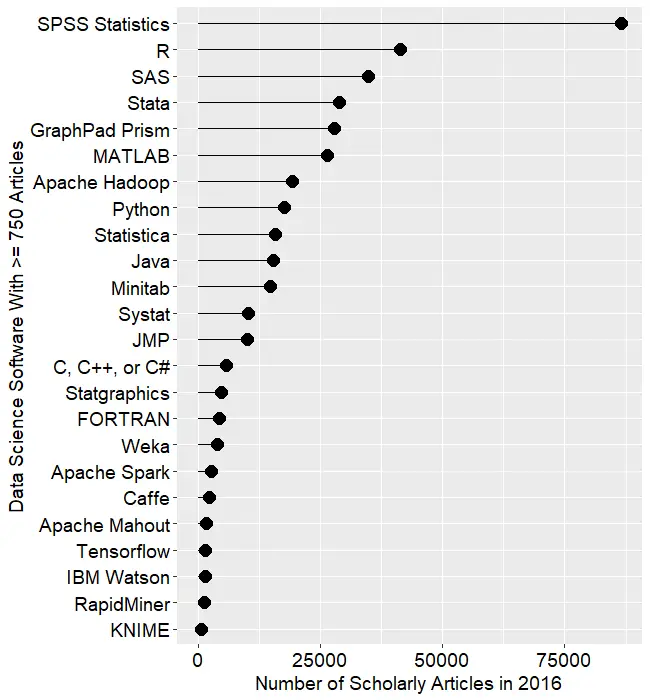
Figure 2a shows the number of articles found for the more popular software packages (those with at least 750 articles) in the most recent complete year, 2016. To allow ample time for publication, insertion into online databases, and indexing, the was data collected on 6/8/2017.
SPSS is by far the most dominant package, as it has been for over 15 years. This may be due to its balance between power and ease-of-use. R is in second place with around half as many articles. SAS is in third place, still maintaining a substantial lead over Stata, MATLAB, and GraphPad Prism, which are nearly tied. This is the first year that I’ve tracked Prism, a package that emphasizes graphics but also includes statistical analysis capabilities. It is particularly popular in the medical research community where it is appreciated for its ease of use. However, it offers far fewer analytic methods than the other software at this level of popularity.
Note that the general-purpose languages: C, C++, C#, FORTRAN, MATLAB, Java, and Python are included only when found in combination with data science terms, so view those counts as more of an approximation than the rest.
Figure 2a. Number of scholarly articles found in the most recent complete year (2016) for the more popular data science software. To be included, software must be used in at least 750 scholarly articles.
The next group of packages goes from Apache Hadoop through Python, Statistica, Java, and Minitab, slowly declining as they go.
Both Systat and JMP are packages that have been on the market for many years, but which have never made it into the “big leagues.”
From C through KNIME, the counts appear to be near zero, but keep in mind that each are used in at least 750 journal articles. However, compared to the 86,500 that used SPSS, they’re a drop in the bucket.
Toward the bottom of Fig. 2a are two similar packages, the open source Caffe and Google’s Tensorflow. These two focus on “deep learning” algorithms, an area that is fairly new (at least the term is) and growing rapidly.
The last two packages in Fig 2a are RapidMiner and KNIME. It has been quite interesting to watch the competition between them unfold for the past several years. They are both workflow-driven tools with very similar capabilities. The IT advisory firms Gartner and Forester rate them as tools able to hold their own against the commercial titans, SPSS and SAS. Given that SPSS has roughly 75 times the usage in academia, that seems like quite a stretch. However, as we will soon see, usage of these newcomers are growing, while use of the older packages is shrinking quite rapidly. This plot shows RapidMiner with nearly twice the usage of KNIME, despite the fact that KNIME has a much more open source model.
Figure 2b shows the results for software used in fewer than 750 articles in 2016. This change in scale allows room for the “bars” to spread out, letting us make comparisons more effectively. This plot contains some fairly new software whose use is low but growing rapidly, such as Alteryx, Azure Machine Learning, H2O, Apache MXNet, Amazon Machine Learning, Scala, and Julia. It also contains some software that is either has either declined from one-time greatness, such as BMDP, or which is stagnating at the bottom, such as Lavastorm, Megaputer, NCSS, SAS Enterprise Miner, and SPSS Modeler.
Figure 2b. The number of scholarly articles for the less popular data science (those used by fewer than 750 scholarly articles in 2016.
While Figures 2a and 2b are useful for studying market share as it stands now, they don’t show how things are changing. It would be ideal to have long-term growth trend graphs for each of the analytics packages, but collecting that much data annually is too time consuming. What I’ve done instead is collect data only for the past two complete years, 2015 and 2016. This provides the data needed to study year-over-year changes.
Figure 2c shows the percent change across those years, with the “hot” packages whose use is growing shown in red (right side); those whose use is declining or “cooling” are shown in blue (left side). Since the number of articles tends to be in the thousands or tens of thousands, I have removed any software that had fewer than 500 articles in 2015. A package that grows from 1 article to 5 may demonstrate 500% growth, but is still of little interest.
Figure 2c. Change in the number of scholarly articles using each software in the most recent two complete years (2015 to 2016). Packages shown in red are “hot” and growing, while those shown in blue are “cooling down” or declining.
Caffe is the data science tool with the fastest growth, at just over 150%. This reflects the rapid growth in the use of deep learning models in the past few years. The similar products Apache MXNet and H2O also grew rapidly, but they were starting from a mere 12 and 31 articles respectively, and so are not shown.
IBM Watson grew 91%, which came as a surprise to me as I’m not quite sure what it does or how it does it, despite having read several of IBM’s descriptions about it. It’s awesome at Jeopardy though!
While R’s growth was a “mere” 14.7%, it was already so widely used that the percent translates into a very substantial count of 5,300 additional articles.
In the RapidMiner vs. KNIME contest, we saw previously that RapidMiner was ahead. From this plot we also see that it’s continuing to pull away from KNIME with quicker growth.
From Minitab on down, the software is losing market share, at least in academia. The variants of C and Java are probably losing out a bit to competition from several different types of software at once.
In just the past few years, Statistica was sold by Statsoft to Dell, then Quest Software, then Francisco Partners, then Tibco! Did its declining usage drive those sales? Did the game of musical chairs scare off potential users? If you’ve got an opinion, please comment below or send me an email.
The biggest losers are SPSS and SAS, both of which declined in use by 25% or more. Recall that Fig. 2a shows that despite recent years of decline, SPSS is still extremely dominant for scholarly use.
I’m particularly interested in the long-term trends of the classic statistics packages. So in Figure 2d I have plotted the same scholarly-use data for 1995 through 2016.
Figure 2d. The number of scholarly articles found in each year by Google Scholar. Only the top six “classic” statistics packages are shown.
As in Figure 2a, SPSS has a clear lead overall, but now you can see that its dominance peaked in 2009 and its use is in sharp decline. SAS never came close to SPSS’ level of dominance, and its use peaked around 2010. GraphPAD Prism followed a similar pattern, though it peaked a bit later, around 2013.
Note that the decline in the number of articles that used SPSS, SAS, or Prism is not balanced by the increase in the other software shown in this particular graph. Even adding up all the other software shown in Figures 2a and 2b doesn’t account for the overall decline. However, I’m looking at only 46 out of over 100 data science tools. SQL and Microsoft Excel could be taking up some of the slack, but it is extremely difficult to focus Google Scholar’s search on articles that used either of those two specifically for data analysis.
Since SAS and SPSS dominate the vertical space in Figure 2d by such a wide margin, I removed those two curves, leaving only two points of SAS usage in 2015 and 2016. The result is shown in Figure 2e.
Figure 2e. The number of scholarly articles found in each year by Google Scholar for classic statistics packages after the curves for SPSS and SAS have been removed.
Freeing up so much space in the plot allows us to see that the growth in the use of R is quite rapid and is pulling away from the pack. If the current trends continue, R will overtake SPSS to become the #1 software for scholarly data science use by the end of 2018. Note however, that due to changes in Google’s search algorithm, the trend lines have shifted before as discussed here. Luckily, the overall trends on this plot have stayed fairly constant for many years.
The rapid growth in Stata use seems to be finally slowing down. Minitab’s growth has also seemed to stall in 2016, as has Systat’s. JMP appears to have had a bit of a dip in 2015, from which it is recovering.
The discussion above has covered but one of many views of software popularity or market share. You can read my analysis of several other perspectives here.
What tools do we use most for data science, machine learning, or analytics? Python, R, SAS, KNIME, RapidMiner,…? How do we use them? We are about to find out as the two most popular surveys on data science tools have both just gone live. Please chip in and help us all get a better understanding of the tools of our trade.
For 18 consecutive years, Gregory Piatetsky has been asking people what software they have actually used in the past twelve months on the KDnuggets Poll. Since this poll contains just one question, it’s very quick to take and you’ll get the latest results immediately. You can take the KDnuggets poll here.
Every other year since 2007 Rexer Analytics has surveyed data science professionals, students, and academics regarding the software they use. It is a more detailed survey which also asks about goals, algorithms, challenges, and a variety of other factors. You can take the Rexer Analytics survey here (use Access Code M7UY4). Summary reports from the seven previous Rexer surveys are FREE and can be downloaded from their Data Science Survey page.
As always, as soon as the results from either survey are available, I’ll post them on this blog, then update the main results in The Popularity of Data Science Software, and finally send out an announcement on Twitter (follow me as @BobMuenchen).
The field of data science is changing so rapidly that it’s quite hard to keep up with it all. When I first started tracking The Popularity of Data Science Software in 2010, I followed only ten packages, all of them classic statistics software. The term data science hadn’t caught on yet, data mining was still a new thing. One of my recent blog posts covered 53 packages, and choosing them from a list of around 100 was a tough decision!
To keep up with the rapidly changing field, you can read the information on a package’s web site, see what people are saying on blog aggregators such as R-Bloggers.com or StatsBlogs.com, and if it sounds good, download a copy and try it out. What’s much harder to do is figure out how they all relate to one another. A helpful source of information on that front is the book Disruptive Analtyics, by Thomas Dinsmore.
I was lucky enough to be the technical reviewer for the book, during which time I ended up reading it twice. I still refer to it regularly as it covers quite a lot of material. In a mere 262 pages, Dinsmore manages to describe each of the following packages, how they relate to one another, and how they fit into the big picture of data science:
Alluxio
Alpine Data
Alteryx
APAMA
Apex
Arrow
Caffe
Cloudera
Deeplearning4J
Drill
Flink
Giraph
Hadoop
HAWQ
Hive
IBM SPSS Modeler
Ignite
Impala
Kafka
KNIME Analytics Platform
Kylin
MADLib
Mahout
MapR
Microsoft R Aerver
Phoenix
Pig
Python
R
RapidMiner
Samza
SAS
SINGA
Skytree Server
Spark
Storm
Tajo
Tensorflow
Tez
Theano
Trafodion
As you can tell from the title, a major theme of the book is how open source software is disrupting the data science marketplace. Dinsmore’s blog, ML/DL: Machine Learning, Deep Learning, extends the book’s coverage as data science software changes from week to week.
I highly recommend both the book and the blog. Have fun keeping up with the field!
The Bureau of Labor Statistics projects that jobs for statisticians will grow by 34% between 2014 and 2024. However, according to the nation’s largest job web site, the number of companies looking for “statisticians” is actually in sharp decline. Those jobs are likely being replaced by postings for “data scientists.”
I regularly monitor the Popularity of Data Science Software, and as an offshoot of that project, I collected data that helps us understand how the term “data science” is defined. I began by finding jobs that required expertise in software used for data science such as R or SPSS. I then examined the tasks that the jobs entailed, such as “analyze data,” and looked up jobs based only on one task at a time. I switched back and forth between searching for software and for the terms used to describe the jobs, until I had a comprehensive list of both. In the end, I had searched for over 50 software packages and over 40 descriptive terms or tasks. I had also skimmed thousands of job advertisements. (Additional details are here).
Search Terms
2/26/2017
2/17/2014
Ratio
Big Data
20,646
10,378
1.99
Data analytics
15,774
6,209
2.54
Machine learning
12,499
3,658
3.42
Statistical analysis
11,397
9,719
1.17
Data mining
9,757
7,776
1.25
Data Science
6,873
973
7.06
Quantitative analysis
4,095
3,365
1.22
Business analytics
4,043
2,867
1.41
Advanced Analytics
3,479
1,497
2.32
Data Scientist
3,272
974
3.36
Statistical software
2,835
2,102
1.35
Predictive analytics
2,411
1,497
1.61
Artificial intelligence
2,404
794
3.03
Predictive modeling
2,264
1,804
1.25
Statistical modeling
2,040
1,462
1.40
Quantitative research
1,837
1,380
1.33
Research analyst
1,756
1,722
1.02
Statistical tools
1,414
1,121
1.26
Statistician
904
1,711
0.53
Statistical packages
784
559
1.40
Survey research
440
559
0.79
Quantitative modeling
352
322
1.09
Statistical research
208
174
1.20
Statistical computing
153
108
1.42
Research computing
133
97
1.37
Statistical analyst
125
141
0.89
Data miner
34
19
1.79
Many terms were used outside the realm of data science. Other terms were used both in data science jobs and in jobs that require little analytic skill. Terms that could not be used to specifically find data science jobs were: analytics, data visualization, graphics, data graphics, statistics, statistical, survey, research associate, and business intelligence. One term, econometric(s), required deep analytical skills, but was too focused on one field.
The search terms that were well-focused on data science, but not overly focused in a single field are listed in the following table. The table is sorted by the number of jobs found on Indeed.com on February 26, 2017. While each column displays counts taken on a single day, the large size of Indeed.com’s database of jobs keeps its counts stable. The correlation between the logs of the two counts is quite strong, r=.95, p= 4.7e-14.
During this three-year period, the overall unemployment rate dropped from 6.7% to 4.7%, indicating a period of job growth for most fields. Three terms grew very rapidly indeed with “data science” growing 7-fold, and both “data scientist” and “artificial intelligence” tripling in size. The biggest surprise was that the use of the term “statistician” took a huge hit, dropping to only 53% of its former value.
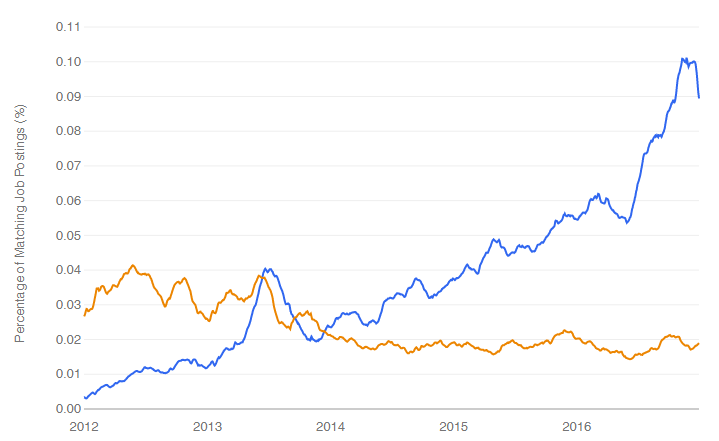
That table covers a wide range of terms, but only on two dates. What does the long-term trend look like? Indeed.com has a trend-tracking page that lets us answer that question. The figure below shows solid the growth in the percentage of advertisements that used the term “data scientist” (blue, top right), while those using the term “statistician” (yellow, lower right) are steadily declining.
The plot on the company’s site is interactive (the one shown here is not) allowing me to see that the most recent data points were recorded on December 27, 2016. On that date, the percentage of jobs for data scientist were 474% of those for statistician.
As an accredited professional statistician, am I worried about this trend? Not at all. Statistical analysis software has broadened its scope to include many new capabilities including: machine learning, artificial intelligence, Structured Query Language, advanced visualization techniques, interfaces to Python, R, and Apache Spark. The software has changed because the job known as “statistician” has changed. Statisticians aren’t going away, their jobs are evolving into what we now know as data science. And that field is growing quite nicely!
One of the best ways to measure the popularity or market share of software for data science is to count the number of job advertisements for each. Job advertisements are rich in information and are backed by money so they are perhaps the best measure of how popular each software is now. Plots of job trends give us a good idea of what is likely to become more popular in the future.
Indeed.com is the biggest job site in the U.S., making its collection the best around. As their co-founder and former CEO Paul Forster stated, Indeed.com includes “all the jobs from over 1,000 unique sources, comprising the major job boards – Monster, Careerbuilder, Hotjobs, Craigslist – as well as hundreds of newspapers, associations, and company websites.” Indeed.com also has superb search capabilities and it includes a tool for tracking long-term trends.
Searching for jobs using Indeed.com is easy, but searching for software in a way that ensures fair comparisons across packages is tricky. Some software is used only for data science (e.g. SPSS, Apache Spark) while others are used in data science jobs and more broadly in report-writing jobs (e.g. SAS, Tableau). General-purpose languages (e.g. C, Java) are heavily used in data science jobs, but the vast majority of jobs that use them have nothing to do with data science. To level the playing field I developed a protocol to focus the search for each software within only jobs for data scientists. The details of this protocol are described in a separate article, How to Search for Data Science Jobs. All of the graphs in this section use those procedures to make the required queries.
I collected the job counts discussed in this section on February 24, 2017. One might think that a sample of on a single day might not be very stable, but the large number of job sources makes the counts in Indeed.com’s collection of jobs quite consistent. The last time I collected this data was February 20, 2014, and those that were collected using the same protocol (the general purpose languages) yielded quite similar results. They grew between 7% and 11%, and correlated r=.94, p=.002.
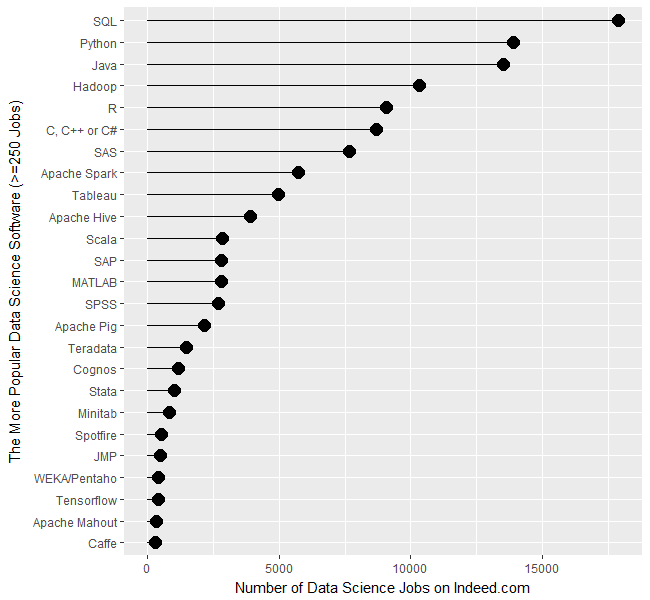
Figure 1a shows that SQL is in the lead with nearly 18,000 jobs, followed by Python and Java in the 13,000’s. Hadoop comes next with just over 10,000 jobs, then R, the C variants, and SAS. (The C, C++, and C# are combined in a single search since job advertisements usually seek any of them). This is the first time this report has shown more jobs for R than SAS, but keep in mind these are jobs specific to data science. If you open up the search to include jobs for report writing, you’ll find twice as many SAS jobs.
Next comes Apache Spark, which was too new to be included in the 2014 report. It has come a long way in an incredibly short time. For a detailed analysis of Spark’s status, see Spark is the Future of Analytics, by Thomas Dinsmore.
Tableau follows, with around 5,000 jobs. The 2014 report excluded Tableau due to its jobs being dominated by report writing. Including report writing will quadruple the number of jobs for Tableau expertise to just over 2o,ooo.
Figure 1a. The number of data science jobs for the more popular software (those with 250 jobs or more, 2/2017).
Apache Hive is next, with around 3,900 jobs, then a very diverse set of software comes next, with Scala, SAP, MATLAB, and SPSS, each having just over 2,500 data science jobs. After those, we see a slow decline from Teradata on down.
Much of the software had fewer than 250 job listings. When displayed on the same graph as the industry leaders, their job counts appear to be zero; therefore I have plotted them separately in Figure 1b. Alteryx comes out the leader of this group with 240 jobs. Microsoft was a difficult search since it appears in data science ads that mention other Microsoft products such as Windows or SQL Server. To eliminate such over-counting, I treated Microsoft different from the rest by including product names such as Azure Machine Learning and Microsoft Cognitive Toolkit. So there’s a good chance I went from over-emphasizing Microsoft to under-emphasizing it with only 157 jobs.
Figure 1b. The number of analytics jobs for the less popular software (under 250 jobs, 2/2017).
Next comes the fascinating new high-performance language Julia. I added FORTRAN just for fun and was surprised to see it still hanging in there after all these years. Apache Flink is also in this grouping, which all have around 125 jobs.
H2O follows, with just over 100 jobs.
I find it fascinating that SAS Enterprise Miner, RapidMiner, and KNIME appear with a similar number of jobs (around 90). Those three share a similar workflow user interface that make them particularly easy to use. The companies advertise the software as not needing much training, so it may be possible that companies feel little need to hire expertise if their existing staff picks it up more easily. SPSS Modeler also uses that type of interface, but its job count is about half that of the others, at 50 jobs.
Bringing up the rear is Statistica, which was sold to Dell, then sold to Quest. Its 36 jobs trails far behind its similar competitor, SPSS, which has a staggering 74-fold job advantage.
The open source MXNet deep learning framework, shows up next with 34 jobs. Tensorflow is a similar project with a 12-fold job advantage, but these two are both young enough that I expect both will be growing rapidly in the future.
In the final batch that has few, if any, jobs, we see a few newcomers such as DataRobot and Domino Data Labs. Others have been around for years, leaving us to wonder how they manage to stay afloat given all the competition.
It’s important to note that the values shown in Figures 1a and 1b are single points in time. The number of jobs for the more popular software do not change much from day to day. Therefore the relative rankings of the software shown in Figure 1a is unlikely to change much over the coming year. The less popular packages shown in Figure 1b have such low job counts that their ranking is more likely to shift from month to month, though their position relative to the major packages should remain more stable.
Each software has an overall trend that shows how the demand for jobs changes across the years. You can plot these trends using Indeed.com’s Job Trends tool. However, as before, focusing just on analytics jobs requires carefully constructed queries, and when comparing two trends at a time, they both have to fit in the same query limit. Those details are described here.
I’m particularly interested in trends involving R so let’s see how it compares to SAS. In Figure 1c we see that the number of data science jobs for SAS has remained relatively flat from 2012 until February 28, 2017 when I made this plot. During that same period, jobs for R grew steadily and finally surpassed jobs for SAS in early 2016. As noted in a blog post (and elsewhere in this report), use of R in scholarly publications surpassed those for SAS in 2015.
Figure 1c. Data science job trends for R (blue) and SAS (orange).
A long-standing debate has been taking place on the Internet regarding the relative place of Python and R. Ironically, this debate about data science software has involved very little actual data. However, it is possible now to at least study the job trends. Figure 1a showed us that Python is well out in front of R, at least on that single day the searches were run. What has the data looked like over time? The answer is shown in Figure 1d.
Figure 1d. Jobs trends for R (blue & lower) and Python (orange & upper).
As we see, Python surpassed R in terms of data science jobs back in 2013. These are, of course, very different languages and a quick scan of job descriptions will show that the R jobs are much more focused on the use of existing methods of analysis, while the Python jobs have more of a custom-programming angle to them.